Contributing Analysts: George Gilbert
Premise
The big data market continues to mature. While users continue to rely on specialized tools from specialized providers, vendor leadership changed little in core big data software, hardware, and services markets in 2016. See the companion report Wikibon 2017 Big Data and Analytics Forecast for the market development roadmap for the next decade.
2016 Big Data Market Share Overview
Table 1 shows that the overall big data market grew 22% from $23.0 billion in 2015 to $28.1B in 2016. While the 2016 Top 10 vendors differed slightly from those in our 2015 report, the growing prominence of public cloud offerings (i.e., AWS and Azure) had the net effect of boosting the overall growth rate of the top 10 vendors to 30%, with the remaining vendors growing more slowly at 19%.
This year, we have combined the big data revenues of Dell, EMC, Pivotal, and VMware into a single Dell figure. This figure represents the hardware, software, and professional services offerings of these four heretofore separately accounted-for entities. As such, the Top 10 now represents 35% of big data market revenue, up from 33% in 2015 – far from consolidation – but indicating a market where the solution offerings are beginning to firm up.
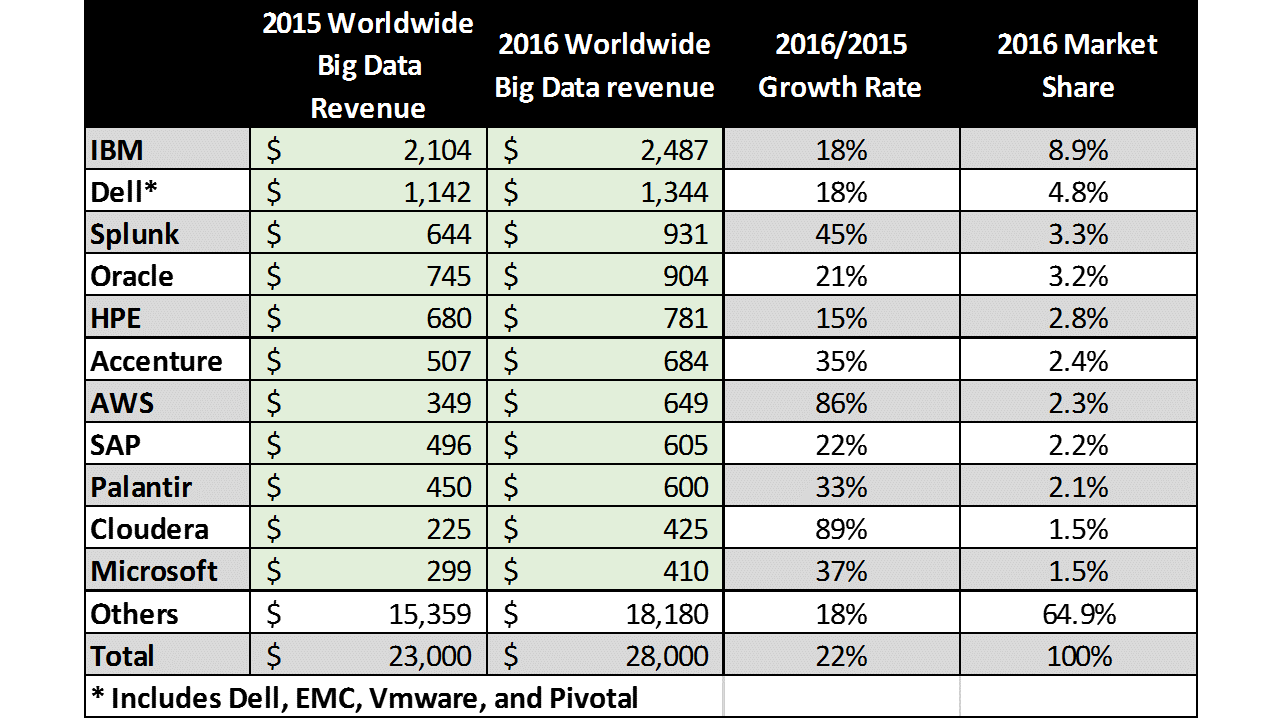
Table 1 – 2016 Big Data Hardware, Software, and Services Revenue ($M) for the Top Vendors, including Revenue and % Market Share
Source: Wikibon 2017 Big Data Project, See Appendix A for All Vendors
With its 8.9% share, IBM maintained its lead in 2016, slightly down from its 9.1% market share in 2015. Among the Top 10, AWS (+0.8% pts), Splunk (+0.5% pts), and Cloudera (+0.5% pts) showed the largest gains in share vs. 2015.
Big data offerings span software, hardware, and services domains. Beyond a handful of market leaders with offerings across the board, most big data providers participate meaningfully in only one of these segments. In the near term, enterprises will be relying on professional services providers to enable their applications. While it has a way to go, Wikibon sees the big data software ecosystem beginning to solidify, enabling users to bear down on solving more big data-related business problems themselves. Application software will replace services as the key market driver in the 2020s.
Vendor leadership in big data is characterized by five classes of vendors:
1) Traditional database and analytics services and software providers. Traditional DBMS suppliers are racing to cross-sell all classes of big data software to existing customers, comprehensive solutions offerings, new big data-oriented offerings, and their vertical expertise.
2) Analytics and tools software providers. Analytics and tools software providers are migrating their expertise to adapt their current offerings and developing specialized tools to accommodate big data requirements.
3) Traditional infrastructure hardware providers. Traditional hardware suppliers bring storage and compute management skills – a key requirement for workloads characterized by high data volume, velocity, variety, and veracity challenges.
4) Public cloud providers. Public Cloud providers bring the merits of tool integration, scalability, low cost sand boxes, and proximity to cloud-based data to the market.
5) Rapidly growing big data software pure plays. Small big data software pure plays are growing faster than the market overall as they address the myriad specialized requirements of big data handling that traditional tools are not meeting.
2016 Worldwide Big Data Software Market Shares
Table 2 shows the top 10 software vendors, which account for 49.4% of the big data software market. While the top vendors have a lot of room for growth, most emerging big data software specialists experienced higher levels of growth in 2016 and will continue to do so in the near future.
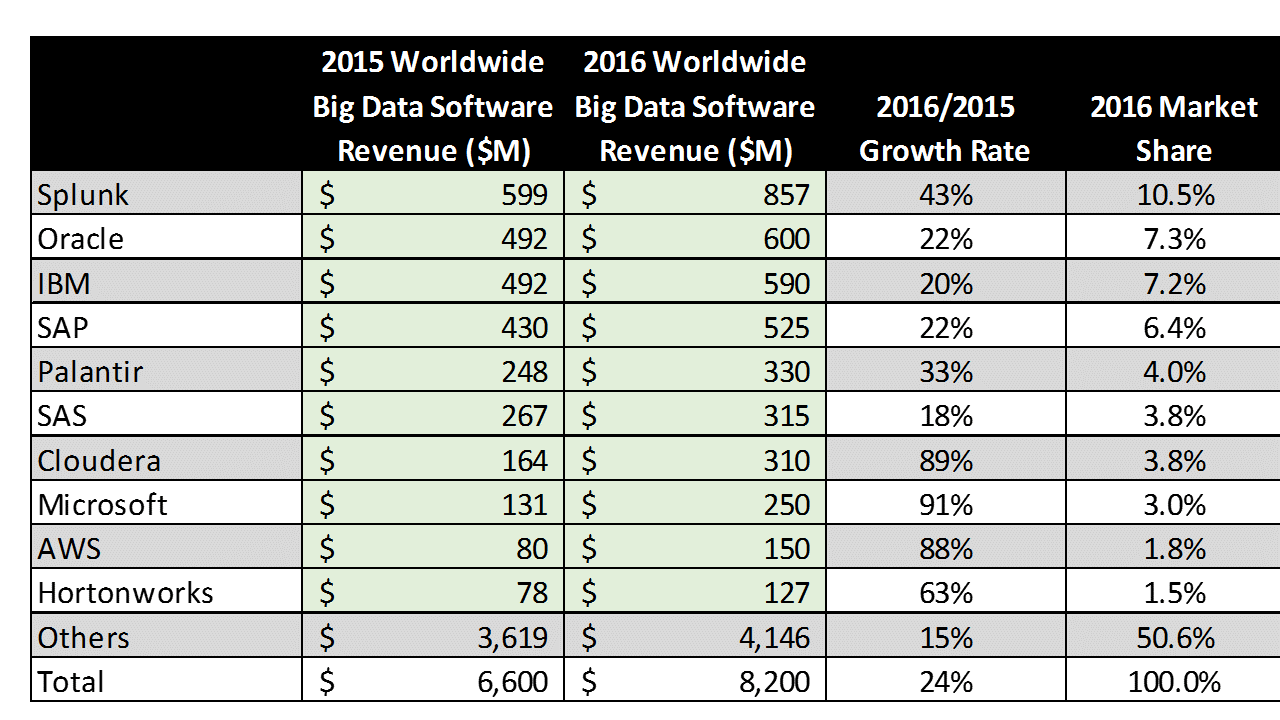
Table 2 – 2016 Big Data Software Revenue ($M) for the Top Ten Vendors, including Revenue and % Market Share
Source: Wikibon 2017 Big Data Project, See Appendix A for All Vendors
In the company summaries below, we explain the vendor-specific business and technology drivers affecting not just their revenues, but why their rankings have changed from 2015 to 2016.
Splunk
- Splunk’s leadership of the software category for 2016 reflects customer recognition that it has become a broad platform for applications built on machine data. Splunk has outgrown its niche as an IT operations application. With close to $900M in software revenue, it is on a collision course with Hadoop. Its revenue is larger than all the independent Hadoop vendors combined and is growing just as fast.
- If Hadoop is an “erector set”, Splunk is more like a furniture shop where all the items like sofas and seats can be arranged in different configurations by the consumer. In the past, most customers saw Hadoop as a more general purpose platform for all big data. Hadoop will always be able to address a greater variety of use cases because it has so many specialized building blocks. But even the largest mainstream enterprises are realizing that the flexible specialization of Hadoop comes at the cost of complexity. As a result, IT is using Splunk for more applications such as audit, cybersecurity, monitoring networks and applications, and increasingly LOB apps.
- Looking forward, Splunk won’t supplant Hadoop completely because Splunk won’t provide analytics that inform transactions. Hadoop applications can be designed to be part of a data pipeline where it provides real-time predictions in support of business transactions. Splunk, by contrast, can collect all the machine data around that business transaction, such as point of sale terminals, the network, the data center infrastructure, and any applications that are involved. Splunk will also be tested by Rocana, the first fully packaged application on Hadoop to address IT operations. Rocana’s success in hiding Hadoop complexity and substituting for Splunk in its core usage scenario would shift more growth in Hadoop’s direction.
Oracle
- Oracle secured its ranking in the top 3 largely because of how it has embraced big data technically and commercially with their flagship database. Oracle’s Big Data SQL software offering has a Hadoop distro, Oracle’s NoSQL database, and Oracle’s version of R. What makes this valuable to Oracle’s existing customers is how their 12c DBMS can query across the data it contains as well as what’s in the Big Data SQL cluster. The Oracle DBMS keeps track of all the data in the big data cluster and uses the same intelligence as the Exadata appliance to push as much of the query down to the data as possible. In other words, customers get open source pricing for their big data and seamless access from 12c’s SQL API and all its data. Oracle also offers an appliance version of the big data suite with extremely aggressive pricing when measured by storage capacity.
- Oracle will attempt to lead efforts to embed advanced analytics in enterprise applications. Predictive analytics is being embedded more within all classes of applications. As Oracle accelerates development and delivery of its various “application clouds” it’s adding advanced analytics in novel ways, including its Data-as-a-Service.
IBM
- IBM is building out its big data stack all the way from industry solutions to PaaS services and its IaaS platform. Below the solutions level, IBM is competitive with AWS, Azure, and Google Cloud Platform (GCP). Wikibon believes IBM’s offerings are having the greatest success when purchased at the solution level, which then brings the entire platform along with it.
- IBM’s big data and machine learning offerings are heavily shaped by its primary go-to-market model: services-rich solutions. IBM is most differentiated in its Watson industry solutions. These solutions require far more customization with professional services or vertical development groups than traditional enterprise apps such as ERP and CRM. Some of the key learnings from each customer engagement make their way into future versions of each solution. While Watson has become a brand that covers virtually all of IBM’s analytics technology, the Watson industry applications drive core customer processes. One example of a sweet spot for IBM is transforming a financial services firm’s customer data into an application that anticipates the risks in financial transactions around individual life events or trading positions.
- The same advantages that are driving IBM’s industry solutions are helping its IIoT solutions get off the ground. IIoT (Industrial Internet of Things) applications require even greater custom development than most current industry solutions. IBM has both the customers from which it can learn and the in-house development and services talent to build those solutions, though the process will probably unfold over the next 5 year time frame.
- The industry applications are largely built on the Watson Data Platform, which competes with otherwise fragmented ecosystems. In general, the 3rd party ecosystem of tools for data scientists, data engineers, business analysts, developers, and administrators is still immature. Customers might be able to experiment with machine learning, but the ecosystem is not yet mature enough to support pipelines that deploy predictive models widely and repeatably into applications. And even if IBM has cracked the design phase, it, too, needs time before it handles the operational side of machine learning.
SAP
- SAP’s ranking comes from its ability to leverage its installed base for ERP and Business Objects customers. Business Objects is providing its installed base, which has been growing since the 1990s, with more discovery and visualization and predictive analytics. SAP is approaching the tools opportunity with big ambitions by trying to manage the full life-cycle of models all the way through operations. However, general BI discovery tools (i.e., Tableau, Qlik, and Power BI) compete strongly here. In addition, big data tool specialists such as Trifacta, Alteryx, Datameer, and Zoomdata have the advantage of not carrying any legacy architectural baggage into the solution.
- SAP is gradually embedding predictive analytics into its apps in order to inform decisions, but its revenue impact will be greater in the future. Predictive analytics requires a different mindset from traditional applications because they don’t code the rules for what should happen within the application. The application data does that over time. So SAP has to go through an internal reorientation in order for its apps to fully leverage advanced analytics. Before the analytic applications can become pervasive, SAP must build out the analytic tooling across its platforms. Not only is machine learning getting fleshed out in Business Objects, but also within their proprietary HANA in-memory DBMS and in the next generation S/4 HANA application suite.
Palantir
- Palantir keeps a very low public profile but it continues to thrive as the largest vendor specializing in building semi-custom machine learning applications for large customers. Palantir has been in the big data and machine learning solutions business for over 10 years and is among the largest vendors solely focused on this technology. While there focus has been national defense and government, they are applying their skills and solutions to the big data problems of commercial users as well.
- Palantir is unlike Accenture and other SIs in that it has core IP that is repeatable across engagements. In this respect, it is more like IBM. As machine learning matures and gets democratized, Palantir’s business model will likely require it to stay up-market in order to continue serving customers with the most demanding, semi-custom solutions.
SAS Institute
- SAS has led the advanced analytics software category for decades. In that time, SAS has built an installed base that has supported it as it goes through the most significant transformation in its history.
- Change is occurring at all levels of SAS’s business and its existing customers are enough to make it to the top 10 of big data software vendors. In terms of customer skills, most graduates today learn advanced analytics with free, open source languages R and Python. From a technical point of view, SAS has been working for years on re-architecting its software to scale out instead of focusing on ever more expensive scale-up servers. SAS believes it put most of this hard work behind them in 2016. From a business model perspective SAS has started migrating from a perpetual license model to metered pricing, which depresses revenues in the early years of the transition. SAS’s success is a testament to its pervasive presence in analytic applications and its large installed base.
Microsoft
- After some false starts, Microsoft is starting to bring its enterprise software installed base into Azure as more workloads become big data-related. The company’s on-premises enterprise software, of itself, is not a great fit for big data workloads. But an increasingly compatible control plane the spans on-prem and cloud workloads is making it easier for customers to add big data workloads on Azure. In fact, Microsoft is increasingly building key data products for Azure first, including SQL Server. For other big data products, Microsoft is “embracing and extending” standards. For example, its Azure Data Lake Store supports and HDFS-compatible API but is far more scalable and performant.
- Azure focuses on how to fit its services together more so than does AWS – and they also offer more “white glove” service to developers than do their cloud competitors. Customers can choose HDInsight for a managed Hadoop service, but they can also use the pre-integrated Azure Data Lake Analytics, SQL DW, Power BI, Stream Analytics, Event Hubs, machine learning models, and cognitive services. Microsoft is progressively integrating these services into Visual Studio for a coherent development environment, in keeping with Microsoft’s historical strategy of making their platforms most attractive to developers. The trade-off is that Azure will be slower to fully integrate new technologies that take off rapidly.
- Microsoft is also leveraging the profitability of its existing enterprise businesses to price Azure services aggressively. As long as its existing enterprise business doesn’t start to shrink dramatically, Microsoft can use its $10bn in annual operating profits to subsidize Azure pricing. Amazon has no such luxury, since its core e-commerce business has really thin operating margins.
Cloudera
- Cloudera used Intel’s $740M investment several years ago to build out its go-to-market footprint. Cloudera might be built on an open source software core, but it has always sold like a large enterprise software company. While free downloads might help with awareness, its “feet on the street”, including 200 sales engineers, drive demand generation. The company targets customers with more than $1bn in revenue and invests more in each initial sale than just a single departmental use case. Sales teams simultaneously sell the platform’s potential so that customers create a more strategic plan for the product enabling Cloudera to go back in with additional applications. Its largest market has been data warehouse augmentation but machine learning is emerging as one of the highest growth use cases with 420 customers already using Spark for machine learning. Long standing customers might have as many as 30-50 production applications. A top 10 bank currently spends $10M/year on subscription support.
- Cloudera’s ecosystem shows its progress in becoming a ubiquitous platform for big data applications. Cloudera has 2,800 partners, including 450 ISV’s with 184 applications on the market. While this thriving ecosystem is a major plus, it also represents a challenge in that Hadoop as an open source project does not offer real portability across distributions because each vendor partially curates a set of projects that are somewhat different. Moreover, Cloudera (as does MapR) also adds some proprietary technology that makes the platform more coherent, it comes at the expense of compatibility.
Hortonworks
- Hortonworks has continued to execute its strategy of rapidly building an installed base of critical mass, even if it means aggressive pricing. Among software providers, Hortonworks has adhered most closely to the ethos of pure open source solutions. It eschews proprietary additions so that customers can feel safe that no part of the platform will be subject to lock-in.
- All the Hadoop vendors are pivoting quickly to offer hybrid cloud options. Even the largest Hadoop customers are struggling with the complexity of an offering that includes a few dozen separate open source projects. Starting in the spring of 2016 customers began to plan to have at least some of their Hadoop capacity in public clouds. While public cloud deployments offer lower TCO, there will be challenges since public cloud vendors have their own Hadoop offerings. For instance, Azure’s Hadoop service, HDInsight, is based on Hortonworks’ distribution. But Hortonworks does have an advantage in at least one respect – the public cloud vendors also have competing, proprietary services. AWS customers, for example, have made S3 more ubiquitous as commodity storage than even HDFS. In addition, the independent Hadoop vendors will have a huge inter-operability matrix to deliver in order to be good citizens across multiple, incompatible clouds.
2016 Worldwide Big Data Hardware Market Shares
Branded hardware is led by the usual server, storage, and networking vendors. Dell (including EMC), HPE, IBM, Cisco, Oracle, and NetApp each have an assortment of server, storage, network offerings, and/or appliances that provide the infrastructure for big data, especially for enterprises, at varying levels of convergence. We are counting AWS’s IaaS offerings as hardware (as we do for Microsoft Azure, Google GCP, IBM Softlayer, and others) since they serve the same function as on-premise hardware services – but are delivered through an alternative channel. A portion of IBM’s hardware market share is similarly accounted for.
Hardware markets are more concentrated overall than software and services markets. While the big data hardware leaders include the usual suspects, ODMs (original design manufacturers) like Amazon and Facebook procure semiconductor, board, and custom built component hardware to support their own big data applications. They are far more prominent in this market than the IT market in general. These cloud service providers who architect and build their own platforms are leading users of big data for adtech, search, artificial intelligence, recommendation engines, machine learning, and other analytic services.
Table 3 shows the detail. Among the branded leaders, Dell (including EMC) is the leader (9.8%) with HPE following at 6.2%. AWS big data compute and storage revenue nearly doubled in 2016, enabling them to achieve a 5.7% hardware market share. Wikibon expects public cloud providers to gain a more significant share of the market going forward since their ability to integrate complex big data functionalities with minimal investment risk. On the other hand, the Internet of Things (especially the Industrial segment) will likely require a significant amount of distributed computing to accommodate latency requirements as well as data transmission costs and challenges (see Wikibon’s Industrial IoT and the Edge https://wikibon.com/industrial-iot-and-the-edge/). So this segment will become more interesting over time – including perhaps non-traditional hardware suppliers.
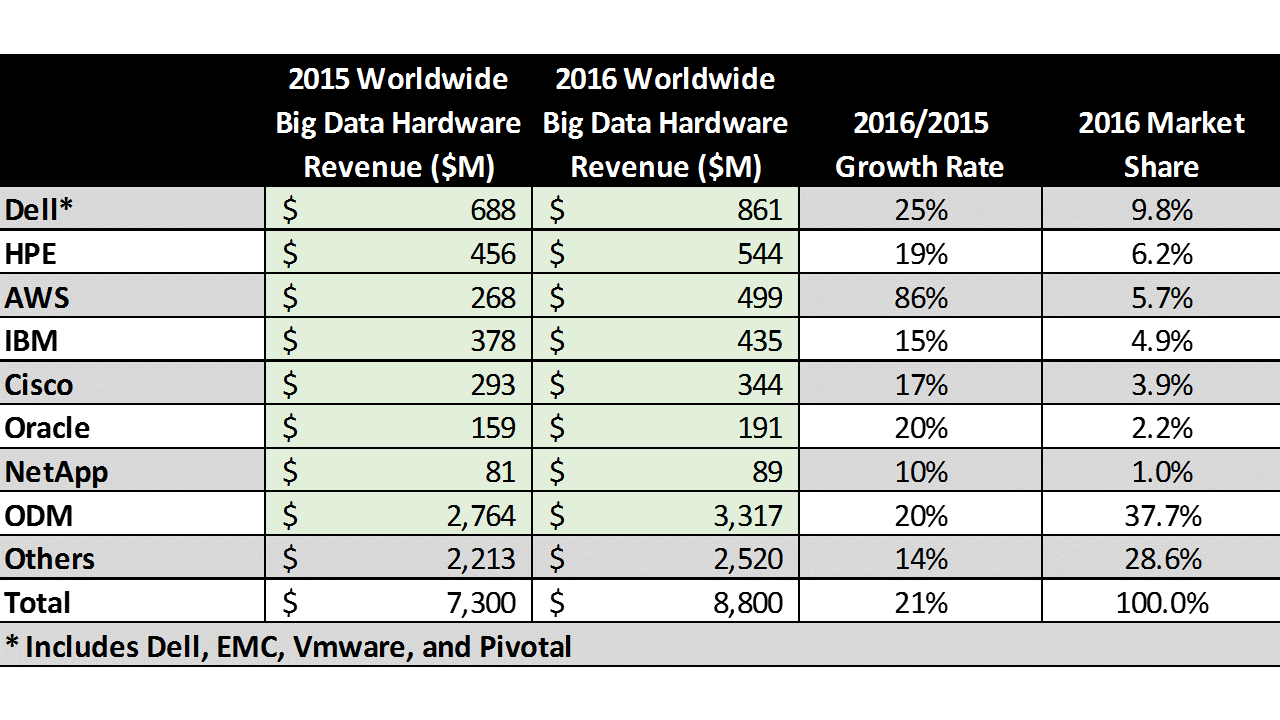
Table 3 – 2016 Big Data Hardware Revenue ($M) for the Top Ten Vendors, including Revenue and % Market Share
Source: Wikibon 2017 Big Data Project, See Appendix A for Detailed Data
2016 Worldwide Big Data Professional Services Market Shares
Professional services is the largest segment of the big data market today and will remain so through 2020. The professional services market is comprised of the following types of vendors:
- First-tier, global IT services providers with the largest scale, widest scope, as well as the highest level of vertical and applications expertise where big data solutions would be applied. IBM and Accenture are prime examples.
- Big data specialists, the largest being Palantir and Mu Sigma
- The 2nd-tier of large IT services providers with the same strategy as tier 1 leaders, but with less breadth such as CSC, PWC, and Deloitte.
- Specialists in adjacent domains that are re-positioning to big data. Teradata (analysis and data warehouses) and Pivotal (development) are representative.
- The hundreds of small professional services with general data warehouse, analytics, business intelligence, and vertical industry expertise that are bringing big data capabilities to their specialized customers.
Table 4 below shows the big data professional services market shares for the top ten vendors, which account for 37.4% of market share. IBM leads with nearly $1.5 billion in revenue, and 13.5% market share. Accenture has nearly $0.7 billion in big data services revenue, for a 6.2% market share.
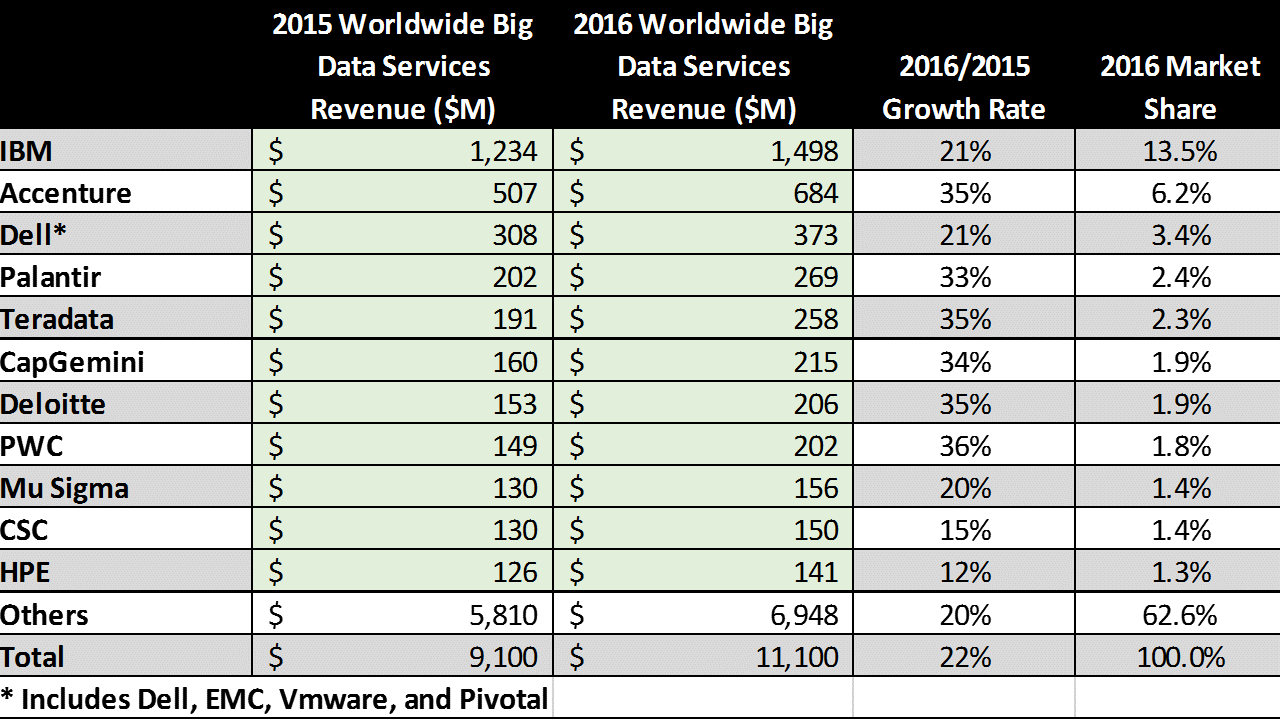
Table 4 – 2016 Big Data Professional Services Revenue ($M) for the Top Ten Vendors, including Revenue and % Market Share
Source: Wikibon 2017 Big Data Project, See Appendix A for Detailed Data
Action Items
Many different vendors provide the multitude of functions, products, and services that make up the big data solution pipeline. Wikibon does not believe that the big data market is a “winner take all” market, but rather will be characterized by the insertion of big data solutions into the myriad of business processes where industry and workload expertise will be the key partnership decision factor. Therefore, the best fit for your enterprise’s big data entry point and/or long term strategy may not be a Top 10 provider. So, choose carefully and consider:
- Product offering quality i.e., reliability, support, stability, breadth and depth of offerings
- Track record for applying their tools and solutions to the specific business requirements for your workload and your industry
- Related business process compatibility, i.e. extensibility to related or adjacent applications and processes
- Incumbent relationships – especially where you have experienced success in related solutions in the past
- An individual enterprise’s risk:reward tolerance or culture for learning, i.e., what’s your appetite for taking a risk, making a mistake, and then recovering or starting over?
Appendix A –2016 Worldwide Big Data Revenue ($M) by Vendor
Table 5 below shows the vendors with 2016 big data revenues of >$40M

Table 5A below shows the vendors with 2016 big data revenues of <$40M


