Premise
Hadoop is a highly scalable, flexible platform for supporting all manner of analytics-focused, data-centric applications. But it was not designed with security or data governance in mind. Security and data governance are critical components to any data platform that hopes to break into the enterprise mainstream. The Hadoop community – both the open source community and the vendor community – have made significant strides in both areas in recent months and years, but more work is needed. It is critical that the Hadoop community come together to solve Hadoop’s security challenges because these are precisely the issues that are and will continue to prevent many practitioners from deploying Hadoop to support production-grade workloads and mission-critical applications.
The Evolution of Hadoop Security
Hadoop has come a long way in just a decade of existence. It was originally developed in 2004 to solve a very specific problem – to help Yahoo! engineers index the world wide web. Since then, Hadoop has evolved into a highly scalable, flexible Big Data platform supporting all manner of data processing workloads and analytics-focused, data-centric applications.
Security, however, was not top of mind when Hadoop was originally developed. There were several reasons for this, including that all the data being indexed by Yahoo! was public-facing and Hadoop was a single-application platform accessed by a select few (trusted) users. At its inception, Hadoop lacked even the most basic security capabilities such as user authentication and basic permission controls. Since then, as Hadoop itself matured to handle new types of workloads and applications, many involving sensitive data, a number of security capabilities have been developed by both the open source and vendor communities.
Unfortunately, these security capabilities have been largely developed in isolation from one another. This is in part because Hadoop itself is not a single technology, but a collection of open source projects, sub-projects and vendor-developed extensions that work together in various combinations to enable different styles of data-centric applications. The result is a hodgepodge of security capabilities that are often difficult to integrate and, due to the relative youth of Hadoop itself, not nearly as mature as security capabilities seen in the traditional data management world.
Hadoop also presents a number of new security challenges that don’t manifest themselves in the world of relational databases and data warehouses. Due to these security limitations and novel security challenges, many early enterprise Hadoop adopters have taken the approach of deploying Hadoop clusters in isolation from the rest of the data management infrastructure (and from each other) and limiting their use to a select few designated users.
This is especially true in use cases where sensitive data from previously disparate sources is commingled. With no simple way to apply fine-grained security controls at a platform level, it is better to lock-down the cluster than risk a security breach or unauthorized access to these sensitive data sets, so the thinking goes. Ironically, in many early adopter environments Hadoop is actually perpetuating the data silo problem that Hadoop is touted as having the ability to fix!
It is critical that the Hadoop community come together to solve Hadoop’s security challenges because these are precisely the issues that are and will continue to prevent many practitioners from deploying Hadoop to support production-grade workloads and mission-critical applications. According to Wikibon’s Big Data Analytics Adoption Survey, 2-14-2015, security concerns were the second biggest obstacle to moving Hadoop into production for practitioners, just behind back-up-and recovery challenges.
The Security Stakes Are High
Why is security so important? To be blunt, there is a lot of money at stake and a Big Data security misstep can cost a company many millions of dollars or even put it out of business. According to the Ponemon Institute, the average cost of a data breach to the targeted company in 2014 was $3.5 million. But, depending on the scale of the breach, the costs can be much higher. Target, which suffered one of the largest known data breaches in 2013, said its breach-related costs were $148 million … in Q2 2014 alone. Total costs to Target could top $1 billion when all is said and done.
But data breaches aren’t the only risk for lax Big Data security. There are myriad national and international regulations that must be adhered to when it comes to how enterprises secure and analyze customer data. In the U.S., for example, HIPAA places strict controls on the use of and security requirements for personal health data. Failure to comply with these requirements – or failure to prove compliance – can result in hefty fines. The compliance environment in the E.U. is even stricter. Failure to comply with the proposed General Data Protection Regulation, which is applicable across vertical industries, could cost offending companies €100 million or more in fines.
In addition to these hard costs associated with data breaches and security compliance, enterprises also have to contend with damage to brand reputation when a major security incident occurs. While quantifying these types of costs is not an exact science, damage to brand reputation and PR fiascos no doubt can have a significant impact on a company’s bottom line and, in some cases, can cost senior executives their jobs.
The Three A’s of Security and Data Protection
So what to do about Hadoop security? In part, security and governance in Hadoop requires many of the same approaches seen in the traditional data management world. These include the “Three As” of security and data protection.
Authentication: Authentication is simply the process of accurately determining the identity of a given user attempting to access a Hadoop cluster or application based on one of a number of factors.
Authorization: Once the identity of a user is determined, authorization is the process of determining what data, types of data or applications that user is allowed to access. This could be based on role, location, time of day, etc.
Auditing: Auditing is the process of recording and reporting what an authenticated, authorized user did once granted access to the cluster, including what data was accessed/changed/added and what analysis occurred.
Data Protection: Data protection refers to the use of techniques such as encryption and data masking to prevent sensitive data from being accessed by unauthorized users and applications.
The Hadoop community has begun to address each of these important areas through both open source projects and vendor-specific solutions. On the authentication front, the Hadoop community early on adopted Kerberos to authenticate Hadoop users, but it was clear from the outset that more needed to be done. Below is a list of current open source projects that individually and collectively attempt to address the above security and data protection issues.
Apache Sentry: Apache Sentry, spearheaded by Cloudera, is a modular system for providing role-based authorization to both data and metadata stored in HDFS in a Hadoop cluster.
Project Rhino: Project Rhino is an Intel-led initiative that aims to provide support for encryption & key management capabilities and a common authorization framework across Hadoop projects and sub-projects.
Apache Knox: Focused on shoring up Hadoop perimeter security and led by Hortonworks, Apache Knox is a REST API Gateway that provides a single access point for all REST interactions with Hadoop clusters.
Apache Ranger: Apache Ranger provides a centralized environment for administering and managing security policies as applied across the Hadoop ecosystem. It is the result of Hortonworks’ acquisition of XA Secure.
Apache Falcon: Led by Hortonworks, Apache Falcon is a Hadoop-based data governance engine that allows administrators to define, schedule, and monitor data management and governance policies.
These open source Hadoop security and governance-focused projects are joined by commercial security products and frameworks from the Hadoop distribution vendors themselves and other vendors in the Hadoop ecosystem. These include subcomponents of particular commercial Hadoop distributions such as Cloudera Navigator for data lineage and data governance, third-party Hadoop data security and governance tools such as DgSecure for Hadoop from Dataguise and IBM InfoSphere Data Privacy for Hadoop, and third-party security frameworks such as WANdisco’s security by cluster separation/tiering model.
Big Data Security Challenges
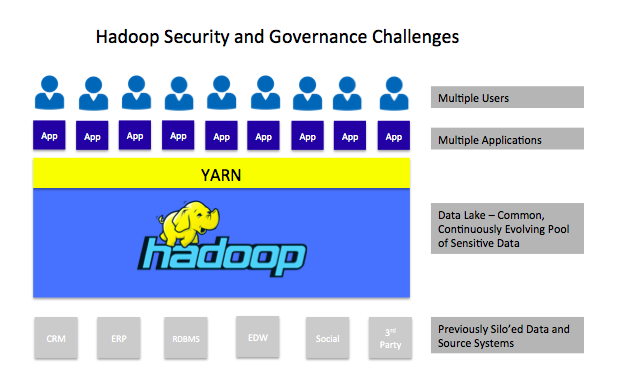
But the the tried-and-true security and governance model epitomized by the three A’s and data protection described above are not enough. Hadoop presents a number of novel security challenges not found in traditional data management environments that will require new approaches. Specifically, one of the most important developments in the evolution of Hadoop was the emergence of Apache YARN, or Yet Another Resource Negotiator. YARN enables a single Hadoop cluster to support multiple applications, significantly enhancing its value to enterprise practitioners. But supporting multiple analytic applications creates new security demands.
Namely, YARN enables Hadoop to function as a multi-tenant environment for Big Data analytics. This has led to the concept of the data lake or data hub. In this scenario, data from throughout an enterprise that was previously stored in silo’ed, secure application environments is brought together in a Hadoop cluster (or virtualized group of clusters) to form a single, comprehensive data landing zone. From there, the same data can be accessed by various analytic applications and users.
In such a scenario, there are multiple authentication and authorization requirements that are not present in a traditional database and data warehouse environments. These include:
-
Different applications require different levels of access to the same data elements. Take social security numbers (SSNs). Some applications will require access to complete SSNs, while others merely require access to the last four digits. Others still should not be allowed any access to SSNs. Flexible authorization and data masking capabilities are required.
-
Just as multiple applications access the same data elements, multiple types of users likewise require varying level of access to data. This requires user authentication and authorization tools that can reconcile and enforce user credentials and permission controls across various user roles and multiple applications.
-
Bringing together previously disparate data types for analysis often results in new data sets that are themselves sensitive. For example, an analytic application running in Hadoop may blend and analyze customer transaction data with social media data and other types of data to determine a person’s proclivity to partake in some risky behavior or predict the likelihood he or she may develop a particular health problem. This requires not just new authorization and governance tools, but a new, proactive approach to data governance by Hadoop practitioners.
Action Item
There is currently no single, unifying approach to Hadoop that brings together solutions to these and other security challenges. The problem is made more confusion by competing Hadoop ecosystem vendors, many of whom take their own proprietary approach to security. It is often, therefore, left to practitioners (and expensive professional services firms) to stitch together the various security approaches native to individual Hadoop components and vendors-spefic tools to approach anything even resembling a platform-level Hadoop security. Wikibon believes this is an unsustainable security model and it is incumbent upon the Hadoop community to work together to solve this challenges. Without a more comprehensive approach, many Hadoop projects are destined to remain perpetually in pilot or PoC status, unable to graduate to full-scale production deployments – which is where Hadoop really starts delivering value.
For vendors, this requires putting the short-term interest of owning the “best” product for Hadoop security aside in favor of working with the open source community, including competing vendors, to develop Hadoop security and governance frameworks that are applicable across the entire Hadoop ecosystem at a platform level. This is ultimately in the best interest of not just Hadoop practitioners but the vendors themselves. Only once practitioners are confident in Hadoop’s security and governance capabilities will they move pilot projects to large-scale production and evolve production deployments to truly enterprise-wide Big Data platform status supporting multiple applications and use cases. And that’s when vendors will start to realize real revenue from their Hadoop-related products and services.
For practitioners, it is important to start thinking about security and governance early in the process of experimenting with Hadoop. There is no shortage of early adopters out there that had to scrap promising Hadoop-based applications because they were unable to implement the level of security and governance controls necessary to safeguard production environments. By considering the security implications of Hadoop use cases at the outset, practitioners will significantly increase their odds of successful outcomes. It is also important for practitioners to play an active role in the larger Hadoop community to aid in the development of platform-level security and governance capabilities. Become active in local Hadoop user groups, provide input on the development of new security and governance approaches via projects such as the recently announced Data Governance Initiative, and push vendors to put the good of the community ahead of short-term self-interest when it comes to Hadoop security and governance.

