Spark and streaming analytics technologies support more sophisticated ways to leverage big data than traditional Hadoop technology because it enables advanced analytics, including machine-learning, within continuously processing application patterns.
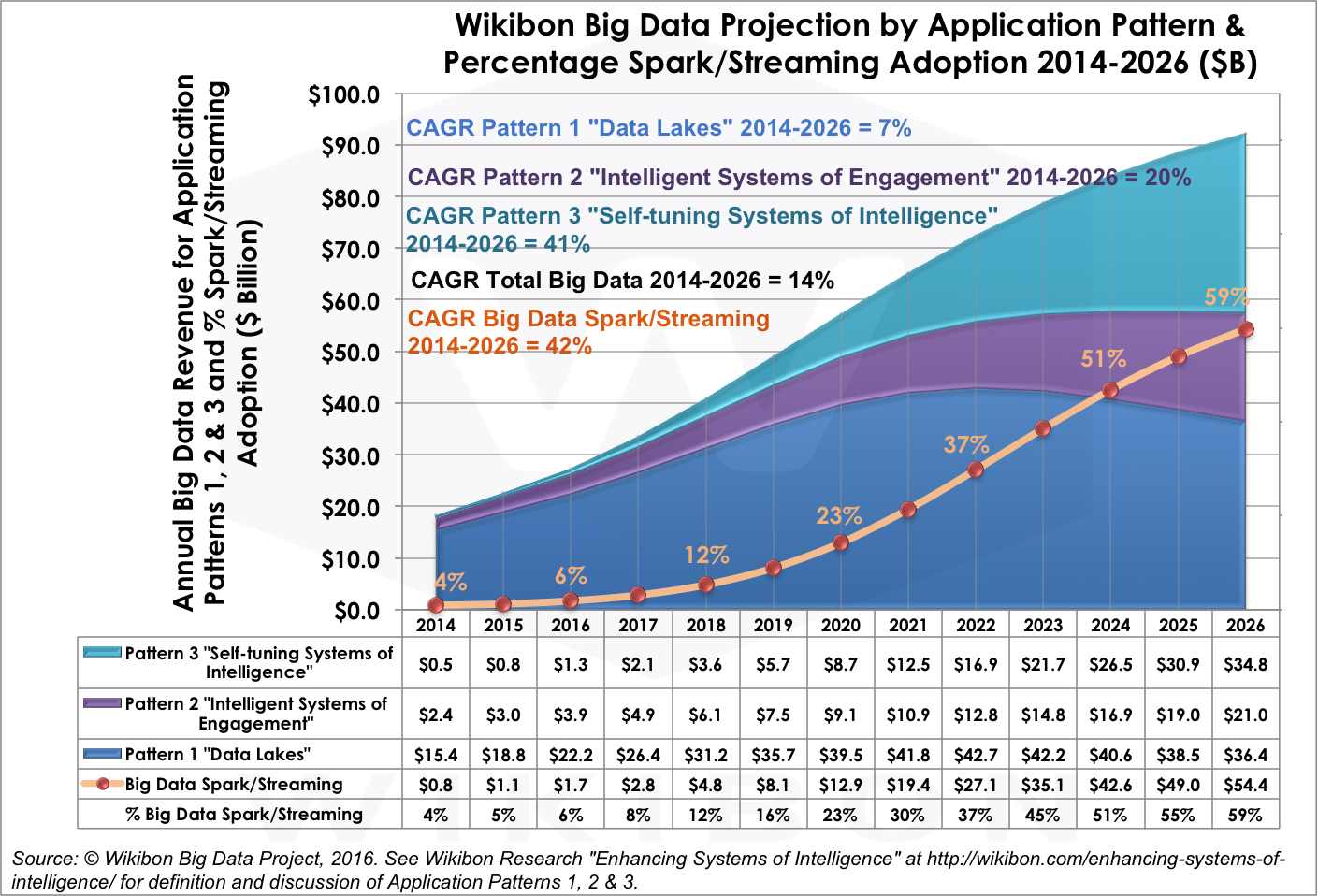
Over the next decade, big data applications will evolve toward continuous, real time processing of vast streams of data. As a result, the role of Spark and related technologies is poised to expand. Wikibon believes Spark will be a crucial catalyst to driving the inflection points for each of Wikibon’s three big data application patterns. In 2016, Spark-based investments will capture 6% of total big data spending, growing to 37% by 2022 because:
- The creators of Spark started with knowledge of MapReduce’s limitations. MapReduce is the low-level “assembly language” of distributed systems programming — but without the speed. Switching metaphors, if an entire program is like a spreadsheet, each cell has to write to disk in order to pass its results to other cells. That worked when memory and bandwidth are limited and when jobs can take hours. But not even the most heroic engineering could overcome those architectural limitations within the constraints of compatibility, time to market, and risk.
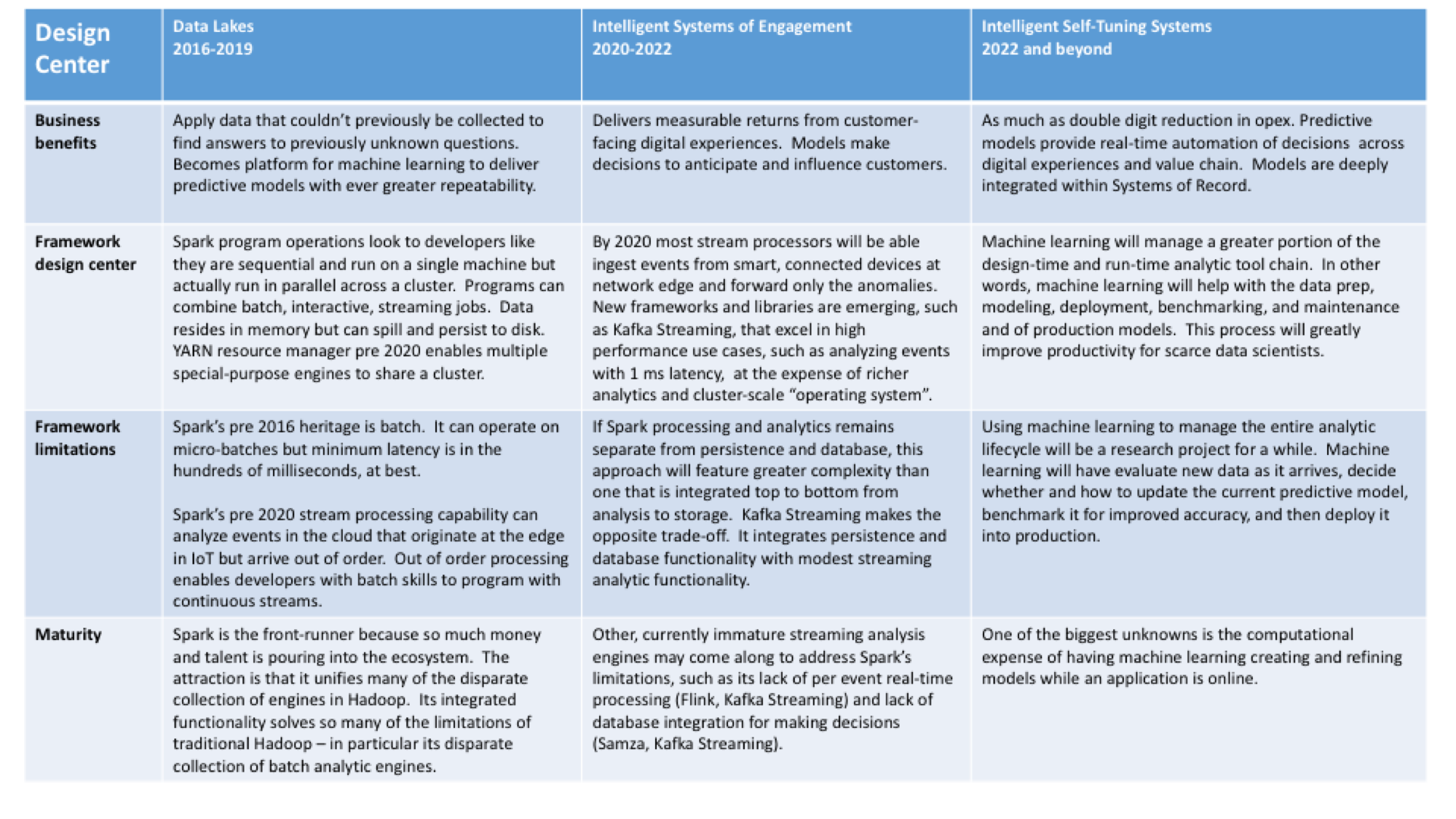
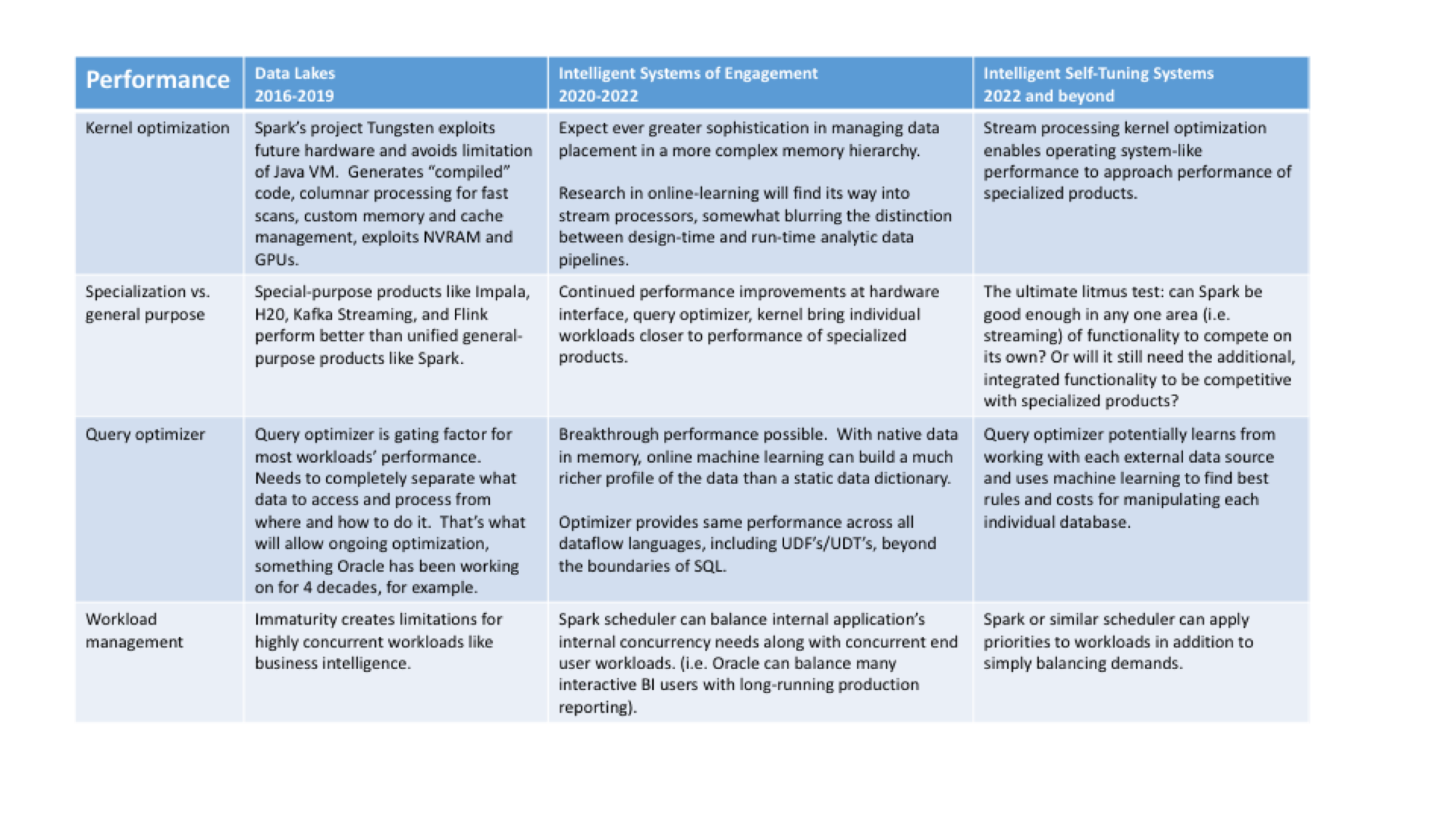
- Spark offers simplicity and performance. Simplicity through unification is progressively replacing the mix-and-match flexibility and complexity of specialized engines that grew up in Hadoop to compensate for MapReduce’s shortcomings. Performance breakthroughs are likely to eventually enable that integrated functionality to approach the speed of specialized products such as dedicated stream processors. Spark assumes memory- and bandwidth-rich systems so it can see the whole dataset at once. Memory-resident operation allows Spark to operate not just at speed, but to optimize operations from beginning to end.
- It’s Spark today, something else tomorrow? Different members of the big data ecosystem are trying to coopt Spark’s popularity and direct investment toward their platforms. The Hadoop vendors are adding the missing filesystem, database and management bits. The major cloud vendors are trying to tightly integrate their native services to further simplify the appeal to developers and admins. And Databricks, the primary steward for the Spark community, is democratizing access by wrapping everything in easy-to-use tools and services. In addition, there are other products in the marketplace at varying levels of maturity that may grow into a significant presence.
Source: © Wikibon Big Data Project 2016
2016-2019: Spark Addresses Hadoop Limitations
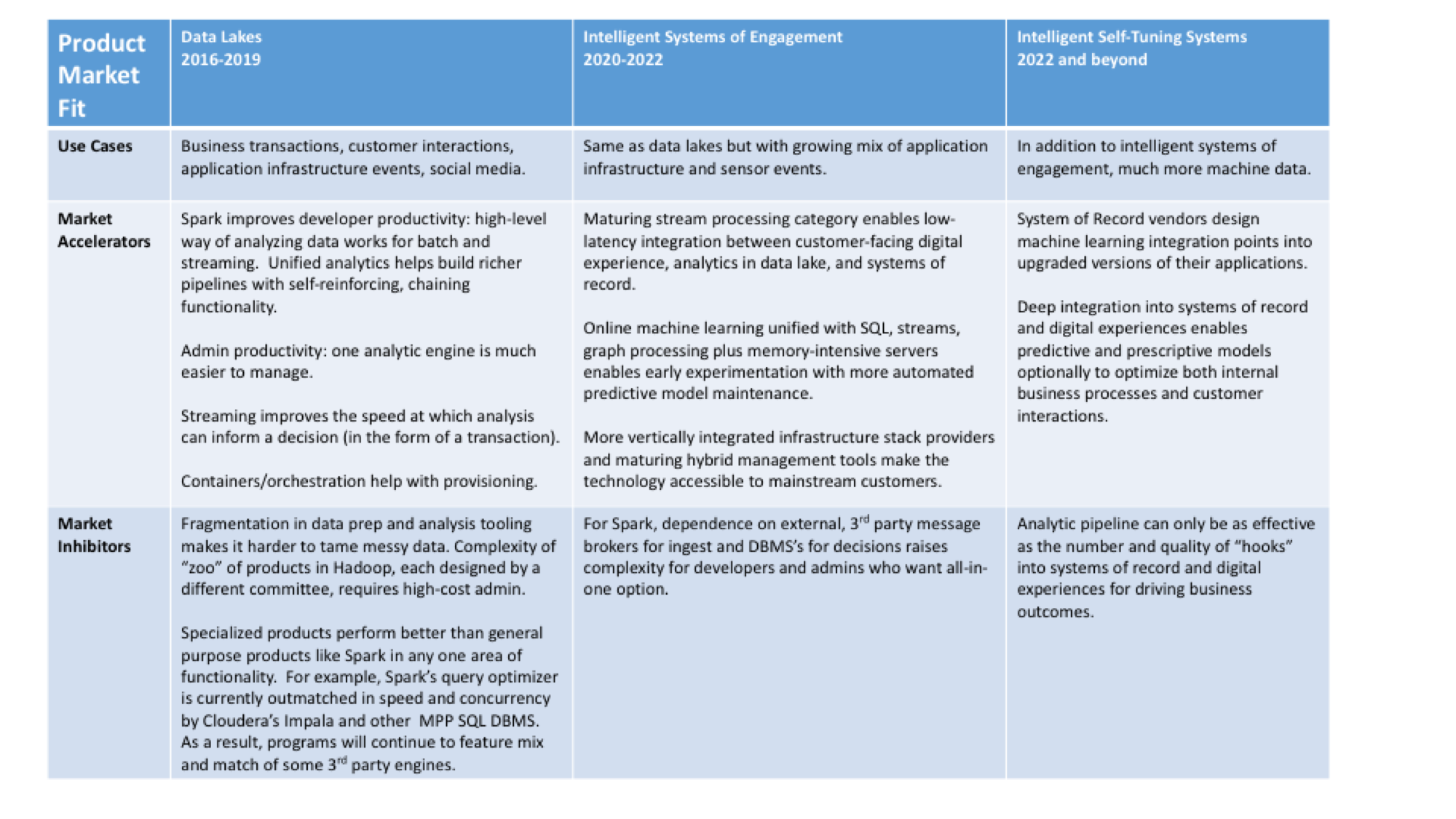
While Hadoop has been synonymous with data lakes, Wikibon forecasts that Spark’s growth rate is accelerating sharply and will hit 72% in 2019. There are several reasons why streaming analytic technology is playing an important role in data lakes. Spark addresses many of the performance and complexity challenges that come with Hadoop’s flexible “zoo” of mix-and-match, batch processing engines. Spark is much simpler for several reasons. Its unified engine can ingest streaming data and chain together different types of analysis and iterate over the data in memory. Chaining makes it possible to do richer analysis, such as recommendations based on a combination of graph processing and machine learning, in previously impossible timeframes.
Spark adoption is not without obstacles. Dedicated engines, such as Impala for business intelligence, still either perform better or are functionally richer in their specialized domains and will probably continue to be for several years. Spark also is not ready for many IoT use cases because it’s footprint is too big and unsuited to operate at the network edge. For example, you can’t interrupt the system and process each event as it arrives. For events that originate at the edge, Spark currently processes the events in the cloud as they arrive, not in their original order. So applications can get wrong answers. The Spark development community is trying to address performance challenges by going around the Java VM directly to the latest hardware and by improving its query optimizer.
2020-2022: Spark Opens Up New Application Opportunities
Developers already seek to integrate customer engagement software with operational applications to create digital customer experiences. Wikibon believes that Spark will be core to this effort — and will fuel overall big data investment between 2020 and 2022. First, Spark will become the design-time foundation for the machine learning that produces the predictive models. Second, Spark will be able to operate these pipelines at run-time fast enough that it’ll be possible to connect customer interactions with the transactional applications that recommend or take a decision. In addition, Spark’s simplified framework will make its integrated analytics more appealing than specialized products for a much greater share of use cases.
However, we see Spark-related risks in this scenario that must be overcome. Although the analytic pipeline that supports digital experiences at run-time will be production-ready by 2020, the design-time pipeline will still be immature. Using machine learning to create, tune, and deploy predictive models will still be far too manual and fragile.
2022 And Beyond: Spark Catalyzes Online Learning Applications
From 2022 to 2026, we expect that machine learning applications will drive the big data market, and that Spark — again — will be crucial. By 2026, 59% of all big data spending will be tied to Spark or related streaming analytics as enterprises seek to deploy applications that can make decisions on behalf of individuals. Moreover, we believe that Spark will be used to dramatically alter the planning, building, and running of big data operations by automating many tasks performed by data engineers and data scientists, including tuning, improving, and benchmarking new models.
The principal technical challenge to building this class of operations will be the need to embed within the core Systems of Record the predictive models that learn while online. Most Systems of Record have limited hooks for analytics, and integrating models that evolve while operating will be a delicate process.
Action Item
Doer’s need to get started early with Spark as a unified streaming analytic engine because each successive application pattern builds on capabilities of the previous one. Unlike earlier application eras, waiting for broadly horizontal packaged applications is less of an option. Systems of Record automated well known internal processes. But the new applications are primarily outward facing and the processes are less well known, making it difficult to create repeatable packages.
Source: Wikibon 2016
Source: Wikibon 2016
Source: Wikibon 2016

