
Premise
The rush of big data, cloud and favorable economics for analytics at scale, are driving demand for insights not possible with existing manual analytical tools. But with a shortage of trained professionals skilled in quantitative methods, the industry is proposing a solution alternatively referred to as “pervasive analytics” or “the democratization of analytics,” pushing advanced analytics farther into the organization with the application of new software tools that advise and automate the complex methods applied. There are benefits and risks to this approach.
Business leaders are eager to make use of advanced analytics. Technology is making it easier; skills availability is making it harder. Some are suggesting “pervasive analytics,” which essentially is greater use of “self-service” system modes to exploit analytic technologies and realize possibilities.
To be successful, pervasive analytics requires much more than just technology. Most prominent is a lack of training and skills on the part of the wide audience that is expected to be “pervaded.” The shortage of “data scientists” is well documented, which is the motivation for pushing advanced analytics down in the organization to business analysts. The availability of new forms of data provides an opportunity to gain a better understanding of customers and business environment (among a multitude of other opportunities), which implies a need to analyze data at a level of complexity beyond current skills, and beyond the capabilities of your current BI tools.
Much work is needed to develop realistic game plans for pervasive analytics. In particular, our research shows that there are three critical areas that need to be addressed:
- Skills and training. A three-day course on analytics technology is not sufficient and organizations need to make a long-term commitment to the development and guiding of analysts.
- Organizing for pervasive analytics.
Existing IT relationships with business analysts need reconstruction and senior analysts and data scientists need to supervise the roles of governance, mentoring and vetting
- Vastly upgraded software from the analytics vendors.
In reaction to this rapidly unfolding situation, software vendors are beginning to provide packaged “predictive capabilities.” This raises a whole host of concerns about casual dragging of statistical and predictive icons onto a palate and almost randomly generating plausible output, that is completely wrong
Skills and Training
Existing business analysts familiar with building reports and dashboards are likely to struggle to learn far more advanced analytic techniques and technologies and understand the underlying math behind probability distributions and quantitative algorithms. However, with a little help (actually, a lot) from software providers, a good man-machine mix is possible where analysts can explore data and use quantitative techniques while being guided, warned, and corrected.
A central concern is how best to train people to be able to build models and make decisions based on probability, not a “single version of the truth.” This process will take longer and require more assistance from those with the training and experience to recognize what makes sense and what doesn’t.
One useful model we’ve seen in practice is allowing these analysts to experiment freely without putting any results into practice until vetted and approved by a mentor. The benefit is that it allows analysts to form hypotheses and peruse them without much bureaucratic overhead.
The state of the art in “automated” AI or ML is not able to prevent serious mistakes from entering in into this sort of analysis yet. Among these are various types of bias, under- or over-training models, misinterpreting results. Even a relatively simple linear regression of two variables can lead to false conclusions (see Figure 1, courtesy of tylervigen.com).
The chart shows a correlation between two seemingly unrelated variables. Not shown, but the correlation coefficient is an almost perfect 0.947, which means the variables are tightly correlated. Be honest with yourself and think about what could explain this? After you’ve thought about a few confounding variables, did you consider that they are both slightly increasing time series, which is the basis of the correlation, not the phenomena themselves? Remove the time element and the correlation drops to almost zero. In other words, what is correlated here is time and slope.
The point here is one doesn’t need to understand the algorithms that create this spurious correlation, they just need enough experience to know that you have to filter out the effect of the time series. But how would they know that?
The fact is that making statistical errors is far more insidious than spreadsheet or BI errors when underlying concepts are hidden. Turning business analysts into analytical analysts is possible, but not automatic.
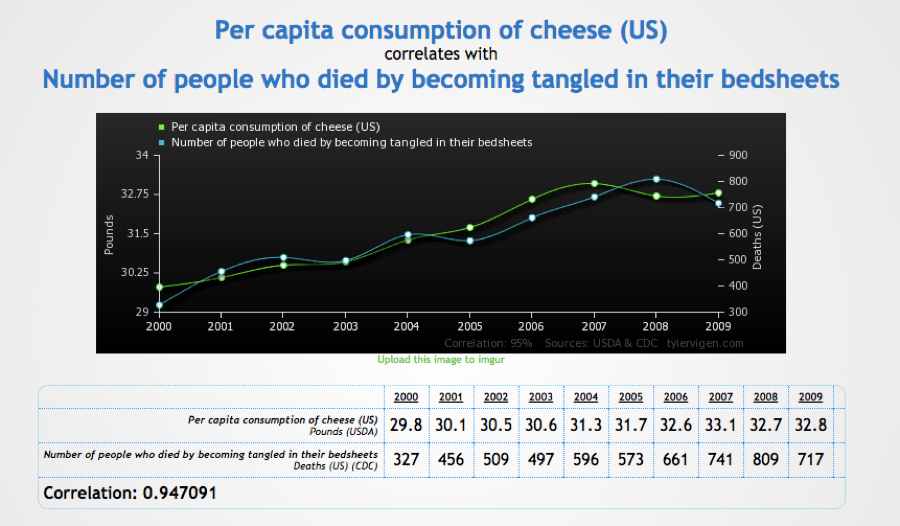
Figure 1. Correlation is not causation.
Organizational: Dealing with DIY Analytics?
The notion of pervasive analytics is new, but one thing is certain: the BI user pyramid has got to go (see Figure 2). In many BI implementations, the work fell onto the shoulders of BI Competency Centers to create datasets, while a handful of “power users” worked with the most useful features of the toolsets. The remainder of the users, dependent on the two tiers above them, generated simple reports or dashboards for themselves or departments. Creating “Pervasive BI” would have entailed doing a dead lift of the “business users” into the “power user” class, but no feasible approach was ever put forward.
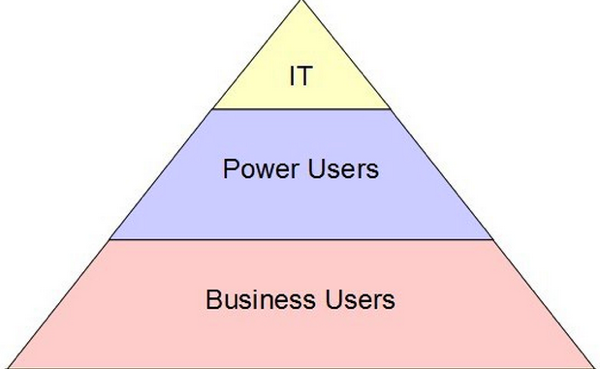
Figure 2. The “BI Pyramid” Doesn’t Always Compute
Pervasive analytics cannot depend on the efforts of a few “go-to guys,” it must evolve into an analytically-centered organization where a combination of training and better software can be effective. That involves a continuing commitment to longer-term training and learning, governance of models so that models developed by professional business analysts can be monitored and vetted before finding their way into production and just a wholesale effort to change the analytics workflow -> where do these analyses go beyond the analyst?
Expectations from Software Providers
Packaged analytical tools are sorely lacking in advice and error catching. It is very easy to take an icon and drop it on some data, and the tools may offer some cryptic error message or, at worst, the “help” system displays 500 words from a statistics textbook to describe the workings of the tool. But this is 2017 and computers are significantly more powerful than they were a few years ago. It will take some hard work for the engineers, but there is no reason why a tool should not be able to respond to its use with:
- Those parameters are not likely to work in this model; why don’t you try these
- Hey, “Texas Sharpshooter”-you drew the boundaries around the data to fit the model
- I see you’re using a p-value but haven’t verified that the distribution is normal. Shall I check for you?
Pervasive analytics will happen, it’s inevitable and even a good idea, but most of the messaging about it has been perilously thin, from Gartner’s “Citizen Data Scientists” to Davenport’s “Light Quants” (who would ever want to be a “light” anything)? What is lacking is some formality about out what kind of training organizations need to commit to, what analytical software vendors need to do to provide extraordinarily better software for neophytes to use productively and, how organizations need to restructure for all of this to be worthwhile and effective.
Action Item
Begin to think about how your organization would be restructured with a large increase in the amount of analytical output, how it would be governed and how it would be consumed. Would it make a difference in the organization’s strategy and decision-making capabilities?

