The ascendency of AWS under the leadership of Andy Jassy was marked by a tsunami of data and corresponding cloud services to leverage data. Those services mainly came in the form of primitives – i.e. basic building blocks that were used by developers to create more sophisticated capabilities.
AWS in the 2020s, led by CEO Adam Selipsky, will be marked by four high level trends in our view: 1) A rush of data that will dwarf anything previously seen; 2) Doubling down on investments in the basic elements of cloud – compute, storage, database, security, etc; 3) Greater emphasis on end-to-end integration of AWS services to make data accessible to more professionals and further accelerate cloud adoption; and 4) Significantly deeper business integration of cloud, beyond IT, as an underlying element of organizational transformation.
In this Breaking Analysis we extract and analyze nuggets from John Furrier’s annual sit down with the CEO of AWS. We’ll share data from ETR and other sources to set the context for the market and competition in cloud and we’ll give you our glimpse of what to expect at re:Invent 2022.
First a Quick Update on the Hyperscale Revenue Forecast
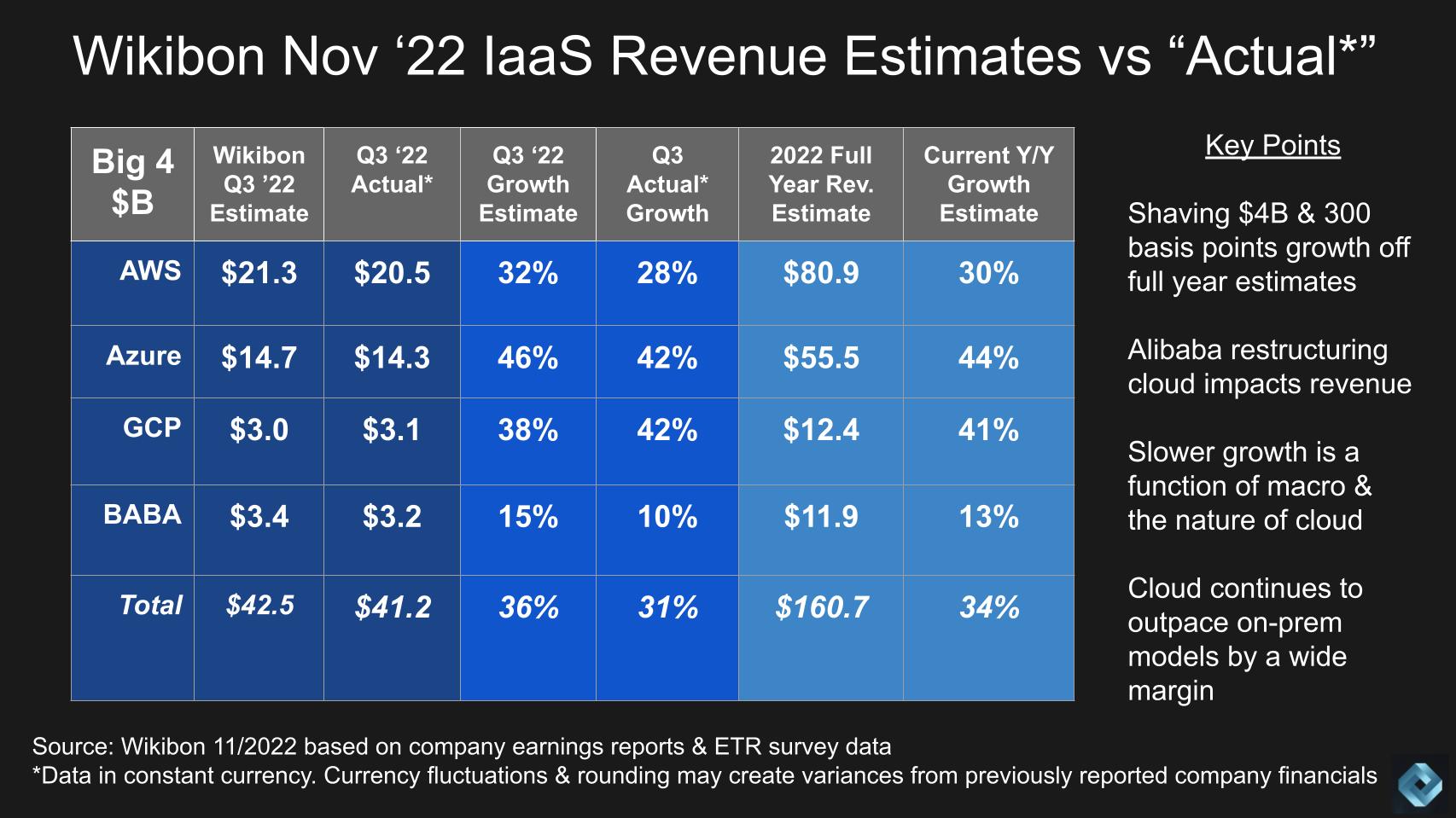
Before we get into the core of our analysis, Alibaba has announced earnings and we’ve updated our Q3 hyperscale computing forecast for the year as seen above.
We won’t spend much time on this but suffice to say Alibaba’s cloud business is suffering from the macro trend but is seeing a more substantial slowdown than its peers. China headwinds combined with a restructuring of its cloud business has led to significantly slower growth for Alibaba. This puts our year end estimates for 2022 revenue at $161B for all four hyperscalers combined. This still represents a healthy 34% growth with AWS expected to surpass $80B in revenue.
Optimizing Cloud Spend is a Durable Trend
On a related note, one of the big themes in cloud that we’ve been reporting is how customers are re-assessing their cloud spend. Below is a graphic we pulled from AWS’ Web site which shows the various pricing plans at a high level. As you know they get much more granular.

Basically there are four levels AWS offers. On-demand – i.e. pay by the drink; spot instances – i.e. right place right time I can use that extra capacity; reserved instances, or RIs, where I pay up front to get a discount; optimized savings plans where customers commit to a one or three year term.
You’ll notice that we labeled the choices in a different order than AWS presents on its Web site and that’s because we believe the natural progression for customers is to start out on-demand, maybe experiment with spot instances, move to RIs when the cloud bill becomes too onerous and if you’re large enough, lock in for one or three years.
We believe on demand accounts for the majority of AWS customer spending. But those on demand customers are also at risk customers. Sure there are switching costs like egress and learning curve but many customers have multiple clouds and if you’re not married to AWS with a longer term commitment there’s less friction to switch.
AWS presents the most attractive plan from a financial perspective second, after on demand and it’s also the plan that requires the greatest commitment.
The Trend Toward Subscription Pricing Models Varies by Sector
In fairness to AWS, it’s true that there’s a trend toward subscription-based pricing. But it’s less pronounced in IaaS than SaaS. This chart below is from an ETR drilldown survey (N=300). Pay attention to the bars on the right. The pink is subscription and the light blue is consumption based. And you can see there’s a steady trend toward subscription.
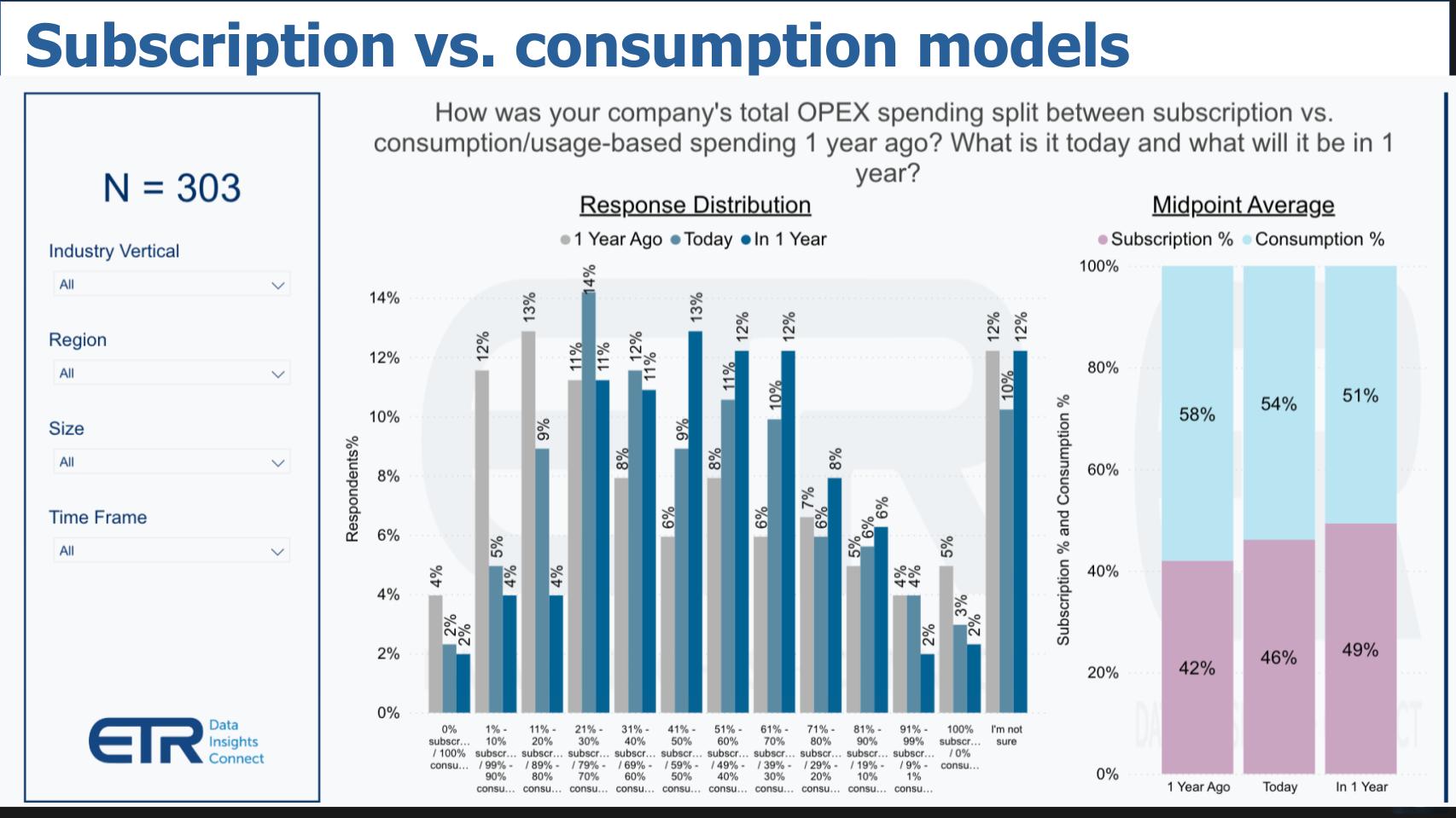
We’ll dig into this in a later Breaking Analysis episode but we’ll share now that when it comes to IaaS and PaaS, 44% of customers either prefer or are required to use on demand pricing whereas around 40% of customers say they either prefer or are required to use subscription pricing. The further you move up the stack the more prominent subscription pricing becomes. Often with 60% or more for software-based offerings requiring or preferring subscription. Notably cybersecurity tracks software likely because, as with software, you’re not shutting down your cyber protection on demand.
Putting Data at the Core of the Business
As a preview to our expectations for re:Invent, we’ll make an an observation related to data.
In his 2018 book Seeing Digital, author David Moschella made the point that, whereas most companies organize data operations on the periphery of their business – almost as an add on function – mega data companies like Google, Amazon and Facebook have placed data at the core of their operations and apply machine intelligence to that foundation.
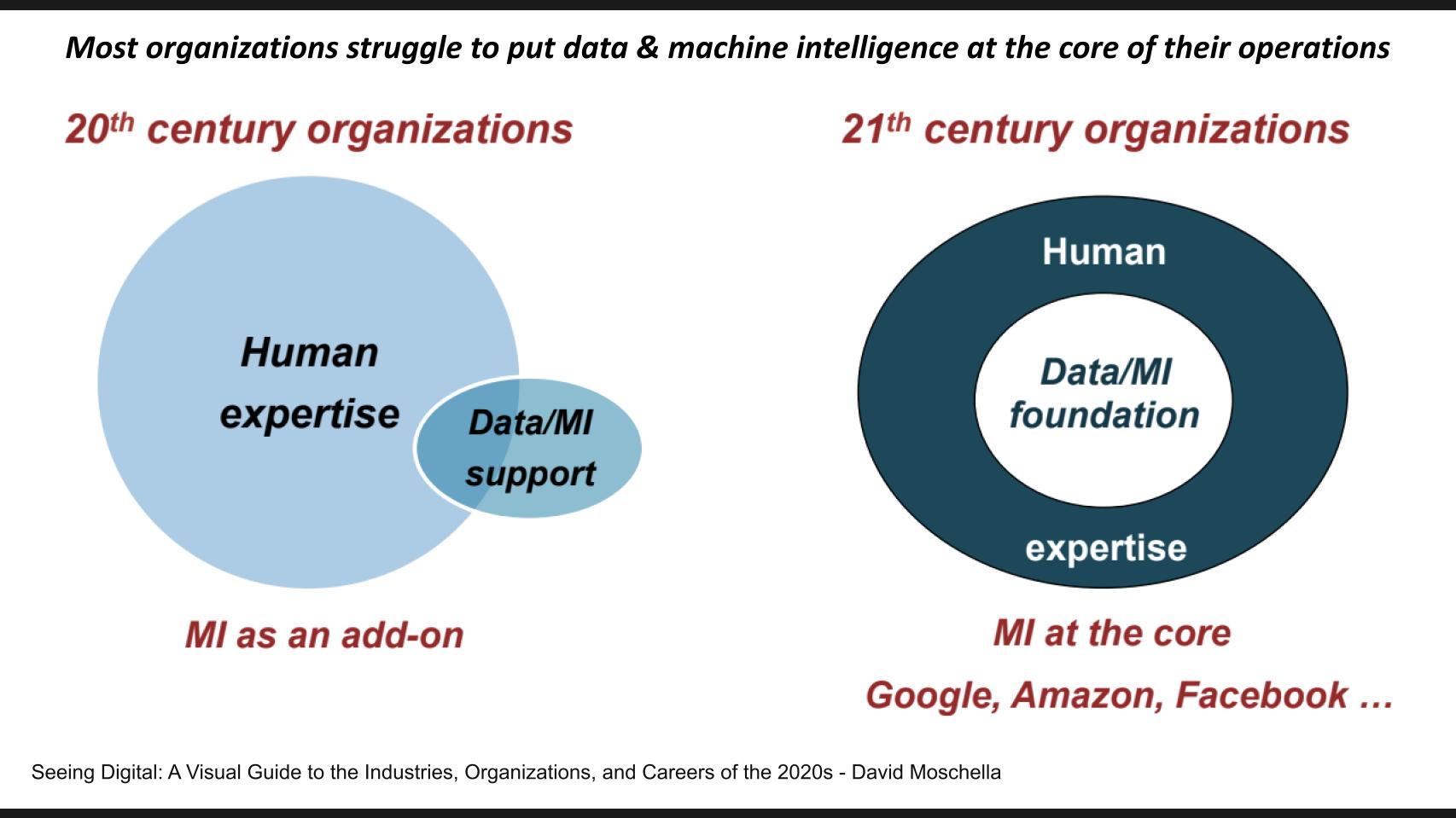
Why is this? The fact is it’s not easy to do what the Internet giants have done.
Embedding Machine Learning & AI into Apps and Data is a Long Term Trend
This brings us to re:Invent 2022 and the future of cloud.
Machine learning and AI will increasingly be infused into applications. The data stack and applications stack are coming together as organizations build data apps and data products. Data expertise is moving from the domain of highly specialized individuals to everyday business people and we are just at the cusp of this trend.
We believe this will be a massive theme of not only re:Invent ‘22 but of cloud in the 2020s. The vision of data mesh will be realized this decade in our view.
Analyzing Nuggets from AWS CEO Adam Selipsky
Let’s now share a glimpse of Adam Selipsky’s thinking. We’ll extract and analyze statements from his sit down with John Furrier. Each year, John has a one on one conversation with the AWS CEO. He’s been doing this for 10 years and the outcome is a better understanding of the directional thinking of the leader of the #1 cloud platform. We’ll first share some direct quotes, run through them with some commentary and then bring in some ETR data to assess the market implications.
The Cloud as a Business Transformer

IT in general and data are moving from departments into becoming intrinsic parts of how businesses function.
Our takeaway is the cloud generally and AWS specifically are moving toward deeper business integration.
In time we’ll stop talking about people who have the word [data] analyst in their title…rather we’ll have hundreds of millions of people who analyze data as part of their day-to-day job, most of whom will not have the word analyst anywhere in their title. We’re talking about graphic designers and pizza shop owners and product managers…and data scientists as well.
Our takeaway here is this speaks to democratizing data and fits with the data mesh trend.
Customers need to be able to take an end-to-end integrated view of their entire [data] journey from ingestion to storage to harmonizing the data to being able to query it, doing business intelligence & human-based analysis to being able to collaborate and share data…and we’ve been putting together a broad suite of tools from database to analytics to business intelligence to help customers with that.
Our takeaways: This last statement is true. However under Jassy, there was not a lot of emphasis on an end-to-end integrated view. We believe it’s clear from these statements that Selipsky is getting direct customer feedback that demands attention to this capability.
Simplify, Minimize Data Movement and Inject Intelligence into the Data Equation
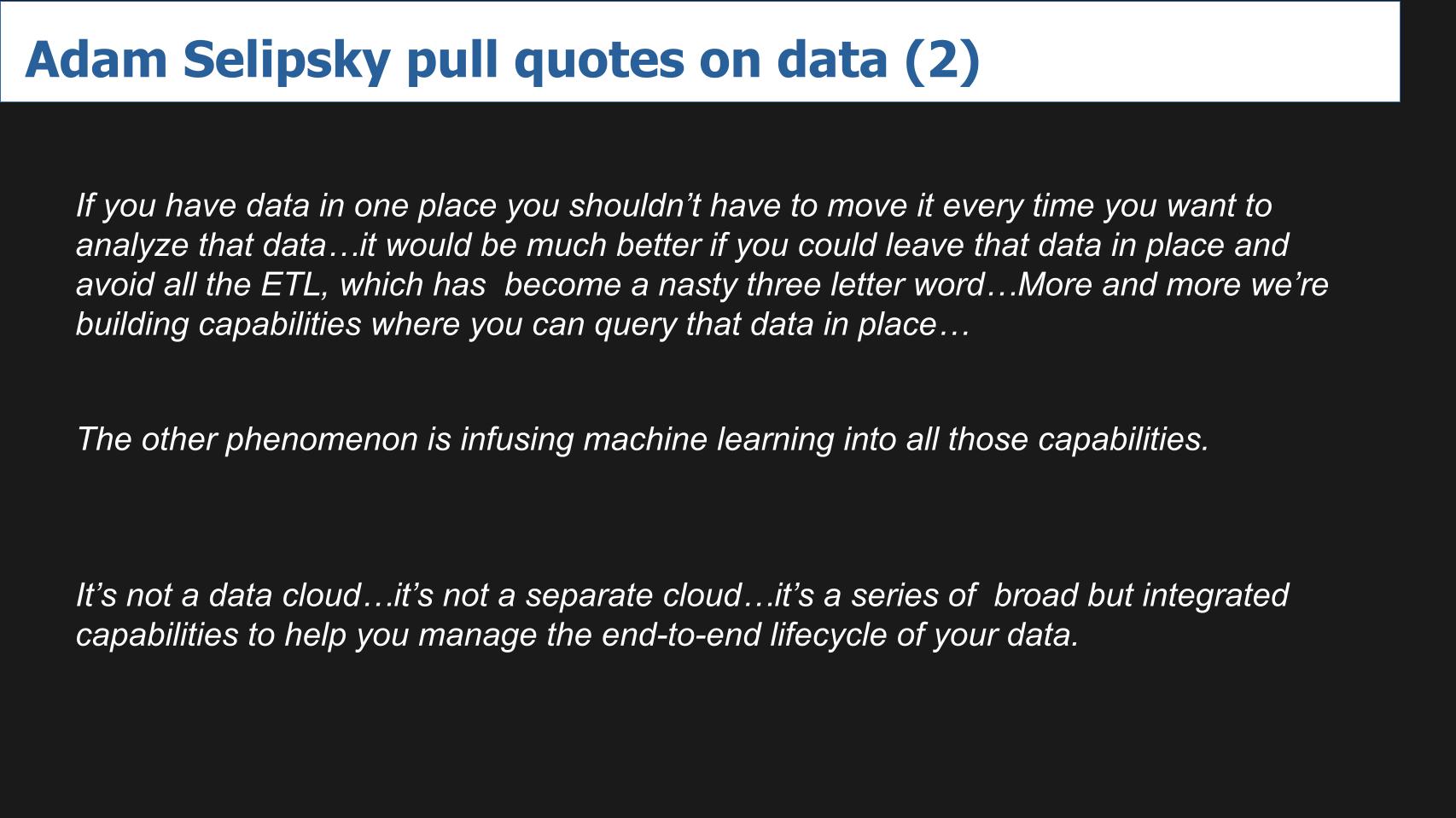
If you have data in one place you shouldn’t have to move it every time you want to analyze that data…it would be much better if you could leave that data in place and avoid all the ETL, which has become a nasty three letter word…More and more we’re building capabilities where you can query that data in place…
Our takeaway: This is a trend we see a lot in the marketplace. Oracle with MySQL Heatwave, the entire trend toward converged database, Snowflake and Mongo extending their platforms into transactions and analytics respectively and so forth.
The other phenomenon is infusing machine learning into all those capabilities.
Our takeaway: Yes the comments from the Moschella graphic above come into play here. Organizations must put data at the core and they’ll do so by deploying intelligent applications and infrastructure.
It’s not a data cloud…it’s not a separate cloud…it’s a series of broad but integrated capabilities to help you manage the end-to-end lifecycle of your data.
Our takeaway: This is a possible blind spot for AWS. In John Furrier’s recent post on his interview with Selipsky, he cited commentary from Ali Ghodsi, CEO of Databricks and Dev Ittycheria, CEO of MongoDB. The notable delta is Selipsky sees these companies and the likes of Snowflake as independent software vendors (ISVs). Both Ghodsi and Ittycheria see themselves as data platforms with a growing ecosystem of ISVs. In our view they are building what we call superclouds on top of AWS and other clouds.
Closing the Data Sharing Gaps
Selipsky’s next commentary that we’ll highlight focused on data governance.

Data governance is a huge issue. Really what customers need is to find the right balance for their organization between access to data and control. And if you provide too much access, then you’re nervous your data’s going to end up in places that it shouldn’t be, viewed by people who shouldn’t be viewing it. And you feel like you lack security around that data. And by the way, what happens then is people overreact and lock it down so that almost nobody can see it.
Our takeaway. Really well put. But today this is a gap for AWS in our view. It’s not easy to share data in a safe way, especially outside of your organization.
Data Clean Rooms – That’s a Good Idea

[Data] Clean room is a really, really interesting area. And I think there’s a lot of different industries in which clean rooms are applicable…I think that clean rooms are an interesting way of enabling multiple parties to share and collaborate on the data while completely respecting each party’s rights and their privacy mandate.
Our takeaway: This is also a gap within AWS today. Sure AWS has RedShift Data Sharing. But that capability only works across clusters for users within the same AWS account. To share data with users on other AWS accounts, they needed to extract it from one system and load it into another– the very process Selipsky alluded to that he’s trying to eliminate.
We know Snowflake is well down this path. And Databricks with Delta Sharing is also on this curve. So AWS has to further address data sharing and demonstrate the capability as part of its end-to-end data integration strategy.
Is it possible AWS will pursue this vision with partners? That would be a powerful combination. But it’s more likely AWS develop its own data sharing capability and continue down a separate partner path as it has in the past.
AWS’ End-t0-End Data Vision = Snowflake + Databricks + IaaS
Let’s bring in some ETR spending data to put some context around this issue with reference points in the form of AWS and its competitors/partners.
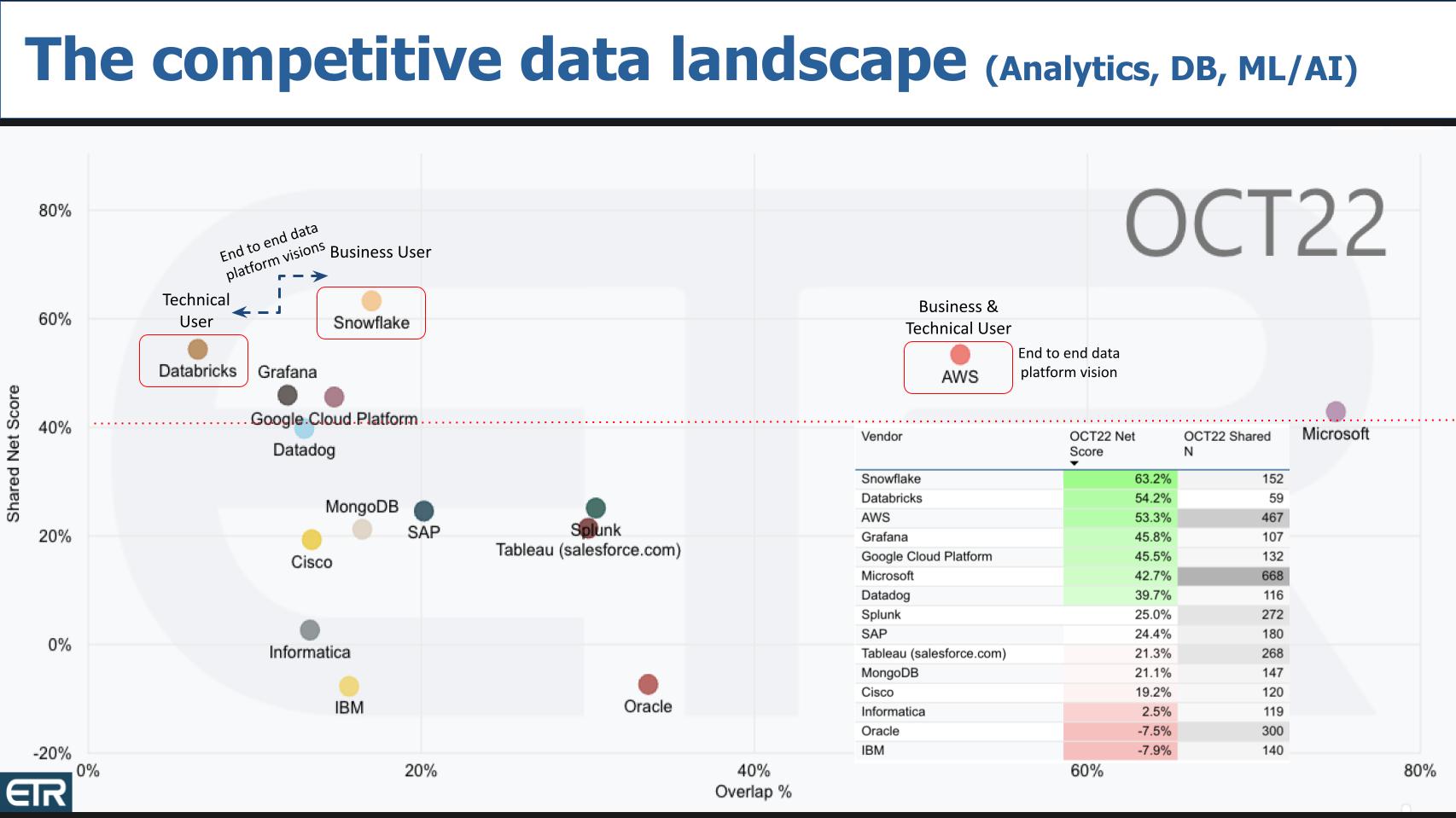
Above is a chart from ETR that shows Net Score or spending momentum on the Y axis and Overlap or pervasiveness in the survey on the X axis. The table insert informs as to how the dots are positioned, Net Score by shared Ns in the survey. We’ve filtered the data on three big data segments: Analytics, database and ML/AI. The red dotted line at 40% indicates highly elevated customer spend.
As usual, Snowflake outperforms all players on the Y axis with a Net score of 63%. Databricks is right behind Snowflake with a robust 53% Net Score. All three big U.S. cloud players are above that line with Microsoft and AWS dominating the X axis. And you see a number of other emerging data players like Grafana and Datadog. MongoDB is solidly in the mix and then some more established players like Splunk, Tableau and Cisco with its network observability offerings.
Then you see the really established players in data like Informatica, IBM and Oracle, all with strong presence but red in the momentum category.
We’ve put a red highlight around Databricks, Snowflake and AWS. Why? Well we feel there’s no way AWS is going to hit the brakes on innovating at the base service level – what we called primitives earlier. Selipsky told Furrier as much in their sitdown. Our premise is that AWS will serve the technical user and data science community, the traditional domain of Databricks; and at the same time address the end-to-end integration, data sharing and business line requirements that Snowflake is positioned to serve. Meanwhile, both Snowflake and Databricks are pursuing a similar vision.
Notably, people often ask us “how will Snowflake and Databricks compete with the likes of AWS?” And we answer by focusing on data exclusively and bringing multicloud to the table. But perhaps the more interesting question is how will AWS compete with the likes of the specialists – Snowflake and Databricks and continue to offer best-of-breed services?
The answer is depicted above. AWS will serve both the technical developer and data science audience and through end-to-end integrations and future services that simplify the data journey for business users.
Ecosystem is AWS’ not so Secret Weapon
The nuance is in all the other dots in the data. And the hundreds or hundred thousand that are not shown here and that’s the AWS ecosystem. You see, AWS has earned the status of the #1 cloud platform that everyone wants to partner with. It has over 100,000 partners in 150 countries and that ecosystem, combined with these capabilities we’re discussing, while perhaps behind in areas like data sharing and integrated governance, can wildly succeed by offering these capabilities and leveraging its ecosystem.
For their part, the Snowflakes, Databricks and Mongos of the world have to stay focused on the mission, build the best products and develop their own ecosystems to compete for and attract the mindshare of both developers and business users. And that’s why it’s so interesting to hear Selipsky basically say these partners are [just] ISVs and this data capability is not a separate cloud, it’s a set of integrated services.
While Snowflake, Databricks and MongoDB (and others) in our view are building superclouds on top of AWS, Azure and Google.
When great products meet great sales and marketing good things can happen so this will be really fun to watch what AWS announces in this area at re:Invent.
The Correlation Between Serverless & Containers
One other topic Selpisky talked about with Furrier was the relationship between serverless and container adoption. We have some observations and data on this that we’d like to share.
Serverless and containers both fit into the story of cost optimization and developer simplicity. Serveless lowers costs by deploying compute resources only when functions are called. But serverless also simplifies the developer’s world by lessening the need for developers to worry about configuring infrastructure.
But before we go to the data, listen to what Andy Jassy said in 2017 on theCUBE talking about serverless and if Amazon had to start over it would build the platform on serverless.
In the very earliest days of AWS Jeff used to say a lot if I were starting Amazon today I have built-in on top of AWS…I think the same thing is true here with Lamda. I think if Amazon were starting today, it’s a given they would build it on the cloud and I think with a lot of the applications that comprise Amazon’s consumer business, we would build those on our serverless capabilities. We still have plenty of capabilities and features and functionality we need to add to Lambda, and our various services, so that may not be true from the get go right now. But I think if you look at the hundreds of thousands of customers who are building on top of Lambda and lots of real applications…people are building real serious things on top of Lambda. And the pace of iteration, you’ll see there, will increase as well and I really believe that to be true over the next year or two. -Andy Jassy
Jassy made that statement five years ago and gave a strong hint that serverless was going to be a key developer platform going forward.
Selipsky referenced to Furrier the high correlation between serverless and containers so we wanted to test that with the ETR data.
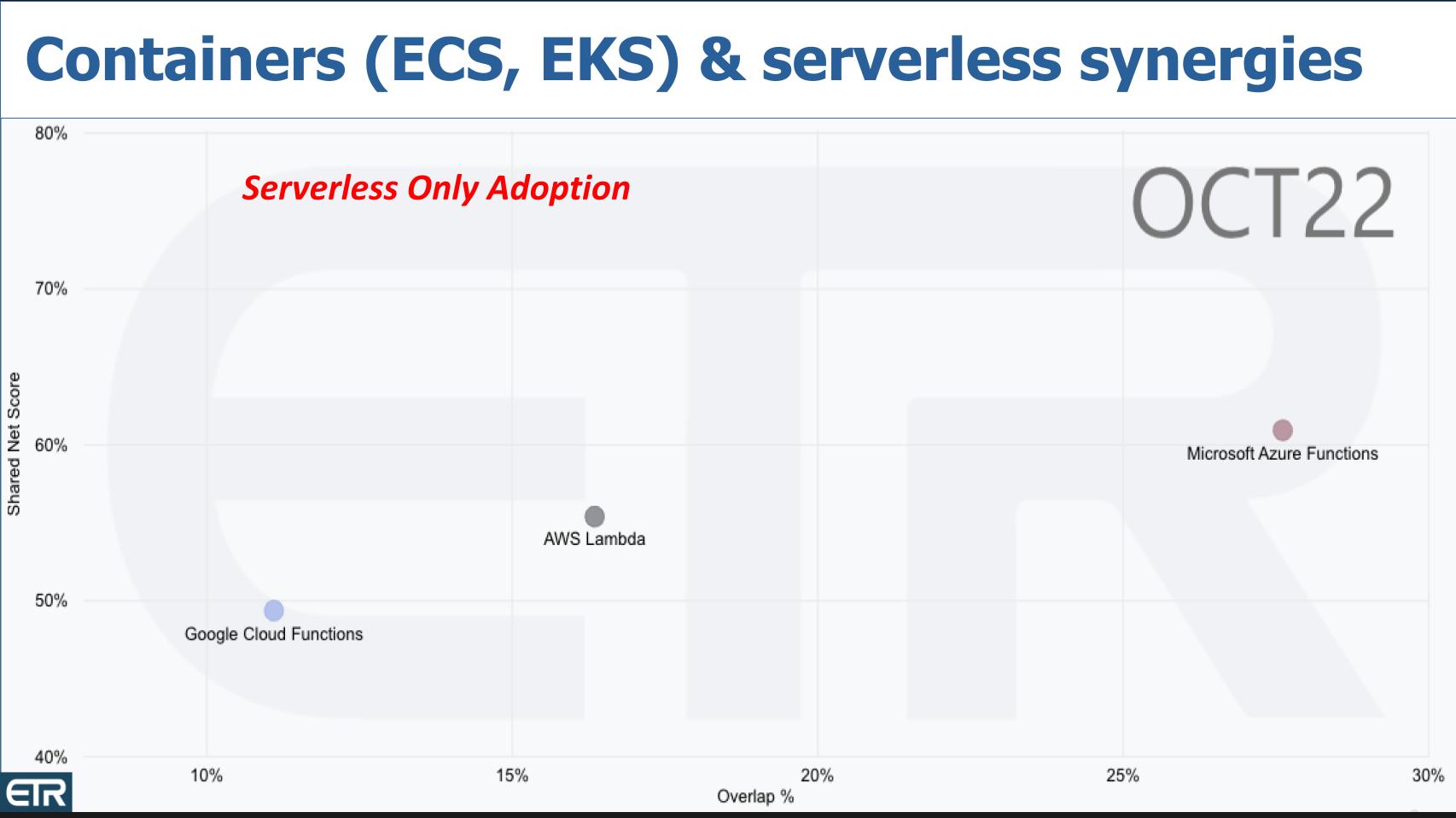
Below is a screen grab of that same XY view across 1300 respondents in the October ETR survey. We’ve isolated on the cloud computing sector and pulled the serverless options for the big three cloud players. You can see Google Cloud Functions, AWS Lambda and Microsoft Azure Functions. On the Y axis is Net Score which is a measure of spending momentum. On the X axis is presence in the data set.
Now remember, anything above that 40% mark is considered highly elevated. So all three serverless platforms are well above that level.
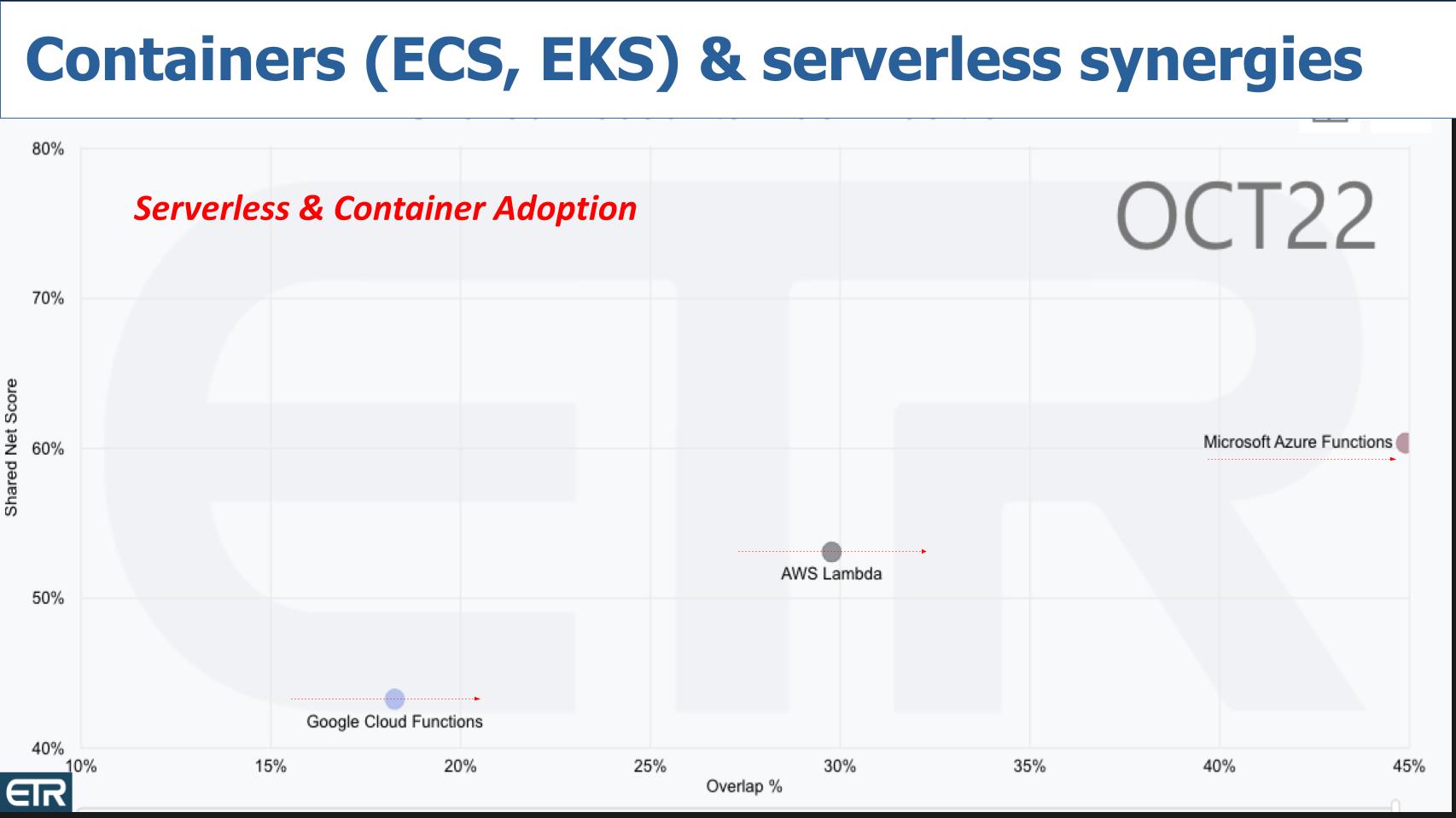
So what we want to do is test the correlation between serverless adoption and momentum, which we’re showing below with container adoption. And the way we do that is we then filter the data on containers to see what happens. And you’ll see all three platforms move to the right. Now the N drops to 443 – i.e. the overlap between those aggressively adopting serverless and those adopting containers.
The first chart is serverless platforms alone and the second chart shows serverless customers who are also adopting containers aggressively. And you can see in the latter chart all three serverless platforms move to the right, signifying a high correlation between the two.
Serverless Adoption Generally
Correlation Between Serverless and Container Adoption
Why Does this Matter? Developer Simplification & Choice
To get a better understanding of what this means we reached out to friend and former CUBE co-host Stu Miniman. What he said was people generally used to think of VMs, containers and serverless as distinctly different architectures but the lines are beginning to blur.
Serverless makes things simpler for developers who don’t want to worry about underlying infrastructure. As Selipsky and the data indicate, serverless and containers are coming together.
As we discussed with Miniman, there’s a spectrum where on the left you have native cloud VMs then in the middle AWS Fargate and the rightmost anchor is Lambda.
Using Containers Without Serverless
Traditionally in the cloud, if you wanted to use containers, developers would have to build a container image, select and deploy EC2 images, allocate a certain amount of memory, fence off the apps in a virtual machine, run the EC2 instances against the app and then pay for all the EC2 resources
AWS Fargate – Simpler but Some Control Over the Runtime
AWS Fargate lets you run containerized apps with less infrastructure management. So with Fargate you’d build the container images, allocate your memory and compute resources run the app and pay for the resources only when they’re used. Fargate lets you control the runtime environment while at the same time simplifying the infrastructure management. And you don’t have to worry about isolating the app and other stuff like choosing server types and patching. AWS does all that for you.
AWS Lambda…Don’t Think About the Underlying Infrastructure
Then there’s Lambda. With Lambda you don’t have to worry about any of the underlying server infrastructure. You’re just running code as functions. So the developer spends their time worrying about the applications and the functions needed.
The point is there’s a movement, as we saw in the ETR data, toward simplifying the development environment and allowing the cloud vendor, AWS in this case, to do more of the underlying management. Some folks will still want to turn knobs and dials but increasingly we’re going to see more higher level service adoption.
re:Invent: Always a Firehose of Content
Let’s do a rapid rundown of what to expect this year at re:Invent 2022.

We talked about optimizing cloud spend and that will undoubtedly be a conversation in the “Hallway Track.”
AWS will continue to deliver on the underlying core infrastructure but we expect messaging around simplifying the experience for organizations. Selipsky is leading AWS into its next phase of growth and that means moving beyond IT transformation into deeper business integration and organizational transformation. And so he’s leading a multi-vector strategy – serving the traditional peeps who want fine-grained access to core services – we’ll see continued innovation in compute, storage, AI, etc. and simplification through both integration and horizontal apps like Amazon Connect.
As we’ve reported many times, Databricks is moving from its stronghold realm of data science into business intelligence and analytics. Whereas Snowflake is coming from its data analytics strength and moving into the world of data science. AWS is going down a path of Snowflake meet Databricks with an underlying cloud IaaS and PaaS layer that puts these three companies on a very interesting trajectory. And you can expect AWS to go right after the data sharing opportunity and in doing so it will have to address data governance in a more complete fashion.
Price performance – a topic that will never go away. One thing we haven’t mentioned today is silicon. It’s a topic we’ve covered extensively on Breaking Analysis from Nitro to Graviton, the AWS acquisition of Annapurna and new specialized capabilities like Inferentia and Trainium. We’d expect something more at re:Invent. Perhaps new Graviton instances. David Floyer said he’s expecting a complete SoC – system on chip – from AWS at some point. An Arm-based server to eventually include high speed CXL connections to devices and memories. All to address next gen applications, lower power requirements and lower cost.
Swami Sivasubramanian will give his usual update on ML and AI, building on Amazon’s years of Sagemaker innovation. Perhaps a focus on conversational AI or better support for vision. And maybe better integration across Amazon’s portfolio and integration of large language models or neural networks and generative AI.
Security. Always high on the list at re:Invent and of course there’s re:Inforce, AWS’ dedicated conference on security. Here we’d like to see more on supply chain security and perhaps how AWS can help. As well as tooling to make the CISOs life easier. But the key so far is AWS is much more partner/ecosystem friendly in the security space than Microsoft traditionally has been. As such, firms like Okta, CrowdStrike and Palo Alto Networks – and many others – have plenty of room to play in the AWS ecosystem.
We’d expect to hear something about ESG and hopefully how not only AWS is helping the environment, that’s important but also how they’ll help customers save money.
And finally – re:Invent is an ecosystem event. It is the superbowl of tech events and the ecosystem will be out in full force. Every tech company on the planet will have a presence and theCUBE will be featuring many of the partners from the show floor.
So you’ll definitely want to tune into thecube.net and check out our exclusive re:Invent coverage. We start Monday evening and go wall to wall through Thursday. We have three sets at the show and our entire team will be there including John Furrier, Lisa Martin, Savannah Peterson and John Walls so please reach out or stop by and say hello.
Keep in Touch
Many thanks to Stu Miniman and David Floyer for their input to today’s episode. And of course John Furrier for extracting the signal from the noise in his sit down with Adam Selipsky. Kudos to Alex Myerson and Ken Shiffman on production, podcasts and media workflows for Breaking Analysis. Special thanks to Kristen Martin and Cheryl Knight who help us keep our community informed and get the word out. And to Rob Hof, our EiC at SiliconANGLE.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com | DM @dvellante on Twitter | Comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail.
Watch the full video analysis:
Note: ETR is a separate company from Wikibon and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai.
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of Wikibon. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.

