Premise. Complexity and administrative cost have slowed the spread of big data applications. The main culprit is too many moving parts, largely owing to the open source origins of most of the components. Special-purpose application performance and operations intelligence (AP&OI) applications designed to manage big data applications can go a long way toward solving this problem. These AP&OI applications use machine learning to embed intelligence that provides high-fidelity root cause analysis along with precise remediation instructions. Depth-first AP&OI applications can work with technology domains beyond big data, but we focus on that domain because depth-first applications build on big data technology.
This report is the third in a series of four reports on applying machine learning to IT Operations Management. As mainstream enterprises put in place the foundations for digital business, it’s becoming clear that the demands of managing the new infrastructure are growing exponentially. The first report summarizes the approaches. The following three reports go into greater depth:
Applying Machine Learning to IT Operations Management – Part 1
Applying Machine Learning to IT Operations Management for End-to-End Visibility – Part 2
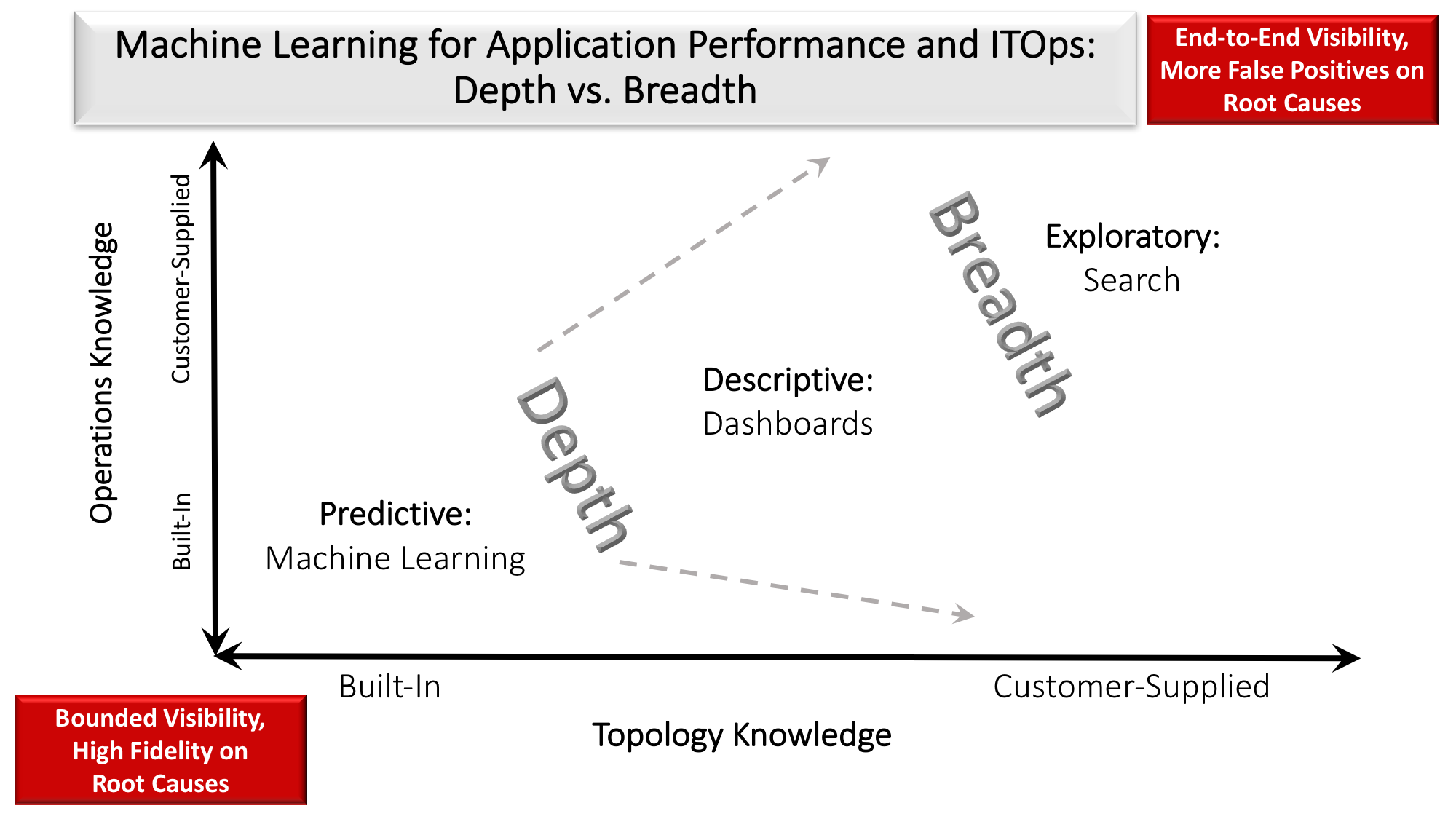
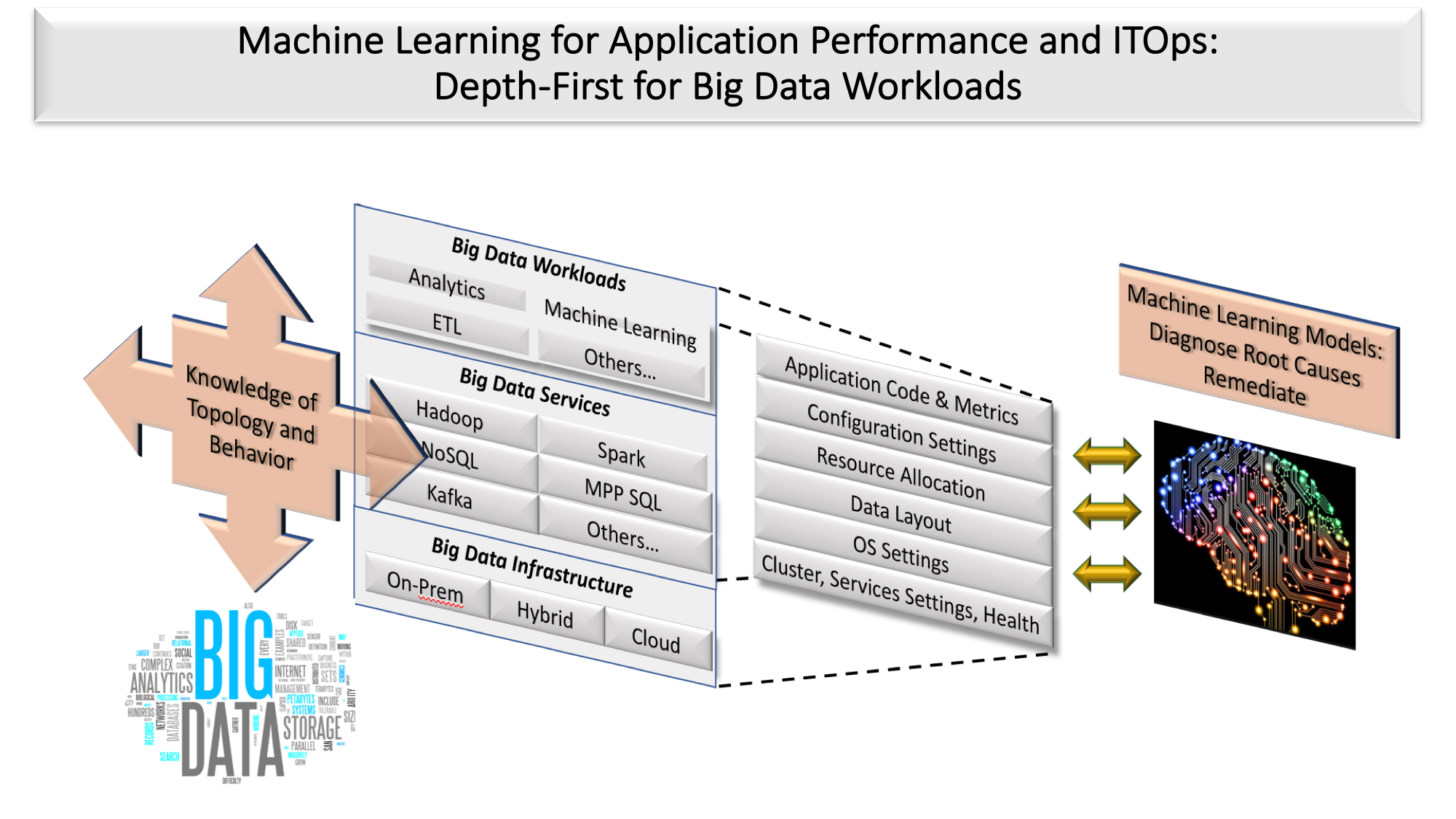
The ability to translate root cause analysis into precise remediation recommendations or automation depends on knowledge of the topology and operation of the application and infrastructure landscape. That knowledge, in the form of machine learning models, can come from two sources. An AP&OI application vendor can build the knowledge in or provide a workbench that the customer can use to add knowledge over time (see figure 1). Depth-first products employ mainly the first approach: they restrict the scope to a technology domain narrow enough to be able to model customers’ relevant topologies and operations. The models enable the precise remediation about what problems to look for and how to fix them when they arise (see table 1). Precise and fast remediation supports the ever more demanding service level agreements for uptime and performance in digital businesses. A depth-first product for big data might include models for streaming analytics and batch processing workloads on Hadoop-related services supported by an elastic cluster of infrastructure (see figure 2).
- Depth-first products deliver the intelligence to pinpoint root causes and recommend precise remediation. Depth-first products model how a set of applications and their infrastructure in a specific domain fit together and operate. The models substitute for specialized administrators from different domains, making it possible to support SLAs with fewer, less specialized administrators.
- Depth-first applications model applications and infrastructure similarly to IoT Digital Twins. Digital Twins in IoT applications model the physics of the real world products they represent. Depth-first applications employ a similar concept in technology domains. Models capture the “physics” of how the applications and infrastructure fit together and operate. Models in depth-first applications will also get deeper with additional learning over time, just like digital twins.
- A depth-first product for big data models big data workloads and everything that supports them. Before a vendor ships the first version of a depth product for big data, they have to train the models on data from years of experience with their design partners. Ultimately, then, the quality of these models is the key evaluation criteria for depth-first products.
- The price for depth-first is the lack of end-to-end visibility. Managing across applications or domains has many of the challenges associated with a breadth-first application. More specialized administrators need to collaborate more intensively to remediate problems.
| Scope of coverage –> | Breadth-first | Depth-first | |
| Built-in knowledge of topology and operation of apps and ITOps | |||
| Examples built on machine learning | Splunk Enterprise Rocana BMC TrueSight |
Unravel Data Extrahop Pepper Data AWS Macie Splunk UBA |
|
| Examples built without machine learning | VMware vCloud Suite New Relic AppDynamics Datadog SignalFX |
CA Network Operations & Analytics | |
| Searchable | Yes | No | |
| BI-style exploration | Yes | Limited | |
| Pre-trained machine learning models | No. Train on customer events, metrics | Yes | |
| Customer extensibility | |||
| Infinite hybrid cloud platform configurations | Yes | No | |
| New apps, services, infrastructure: systems of record, Web/mobile | Yes | No | |
| New events and metrics | Anomaly detection for new time series of events, metrics | No | |
| New visualizations, dashboards | Yes | No | |
| New complex event processing rules | Yes. Based on customer’s domain expertise | Limited | |
| New machine learning models | Some vendors (ex – Splunk) | No | |
| Root cause analysis | |||
| Source of domain knowledge | Customer | Vendor | |
| Alert quantity vs. quality | Quantity: What happened. | Quality: Why things happened. | |
| Scope of contextual knowledge | Identifies failed entities | Identifies failures within and between entities | |
| Likelihood of false positives | High | Low | |
| Machine learning maturity | |||
| Already trained | No | Yes. Using data from design partners | |
| Data science knowledge required | Yes | Minimal |
Table 1: Breadth-first and Depth-first serve distinct — and sometimes tangential Applications Performance and IT Operations Management needs.
Depth-First Delivers the Intelligence to Pinpoint Root Causes and Recommend Precise Remediation.
AP&OI products designed for depth of intelligence come with vendor-trained machine learning models about the topology and operation of the application and infrastructure landscape. The benefit of integrating all this knowledge is that a depth-first product can solve for the root causes of problems with far fewer false positives. By having the AP&OI application understand how everything in a specific domain fits together and operates, administrators don’t have to do manual correlation of metrics and events in their heads. The precision of the root cause analysis, for example, simplifies administration of big data applications. A year ago it was common to hear of Hadoop customers who had 5 admins managing a pilot cluster of 10 nodes. Today, Box has 2 administrators supporting its service with 50 developers building applications.
Depth-First Applications Model Application and Infrastructure Similarly to IoT Digital Twins.
One way to understand the mechanics and benefits of the depth-first approach is to compare it to the concept of the Digital Twin in IoT. A Digital Twin is a data simulacrum of an entity, such as a product, that embodies that entity’s structure and behavior. The structure comes in the form of a hierarchy of component parts. The behavior comes in a set of machine learning models and simulations that operate the way each of the components do. Holding that amalgamation together is a knowledge graph that maps how components fit together structurally and operationally. That knowledge graph gets deeper over time with additional learnings from a single customer or based on pooled experience that vendors can collect.
A Depth-First Product for Big Data Models Big Data Workloads and Everything that Supports Them.
A depth-first product for big data models users; their applications; the big data services supporting those applications; the configuration settings for the services; data topology, usage, and access patterns; and the underlying infrastructure. Because of the narrower, deeper scope, a depth-first product can train its models to represent each entity’s behavior, the interactions between them horizontally across the stack, and the interactions between them vertically up and down the stack. In order for a vendor to embed these models in its product, the vendor needs to accumulate immense volumes of operational data from design partners running similar workloads and services. A vendor building a depth-first big data product might model several Hadoop products such as Tez, MapReduce, HDFS, and YARN. As the models for these services mature, it becomes progressively easier to add new, related services, such as Spark. The depth-first product vendor also has to model the most common big data workloads include analytics, ETL, and machine learning. These patterns build on capabilities for data flow (streaming), periodic or on-demand operation (batch), and request/response (optimized for serving data). So before the vendor ships version 1.0 of their product, the models embody years of experience.
The Price of Depth-First is the Lack of End-to-End Visibility.
A depth-first big data product can diagnose the root cause of a problem with great fidelity and offer a detailed prescription to fix it. But if the same big data application is operating alongside a system of record or a mobile application, diagnosing and remediating a problem requires challenges similar to breadth-first products. Specialized administrators from different domains will have to collaborate in order to analyze the problem from multiple perspectives.
Action Item. If the constraint on your ability to leverage big data is based on the scarcity of administrative skills, don’t automatically assume that cloud deployments are a panacea. Depth-first AP&OI products and services, while relatively new, incorporate many years of experience building the IT operations management-equivalent of digital twins for big data resources. Shops experiencing accelerating big data demand — especially if that demand involves significant integration into operational systems — should consider running a pilot with a depth-first AP&OI product and see if it ameliorates the problem of administrative overhead.

