The AI heard ’round the world has put the machine intelligence sector back in the spotlight. But when you squint beyond the press hype, the data shows that artificial intelligence is now the number one sector in terms of relative spending velocity in the ETR taxonomy. Normally market hype leads deployments, but the data suggests that spending activity and market penetration for AI are coinciding with the hype. While hyperscale cloud players are reaping the rewards, we think this is a rising tide that’s going to lift all AI ships, those both plainly in sight and others that may not be so visible.
In this Breaking Analysis we dig deeper into the AI space with spending data from ETR and one of the best minds in tech generally, and AI specifically, Jeff Jonas, CEO, founder, and chief scientist at Senzing.
After a Lull, AI is Back on Top
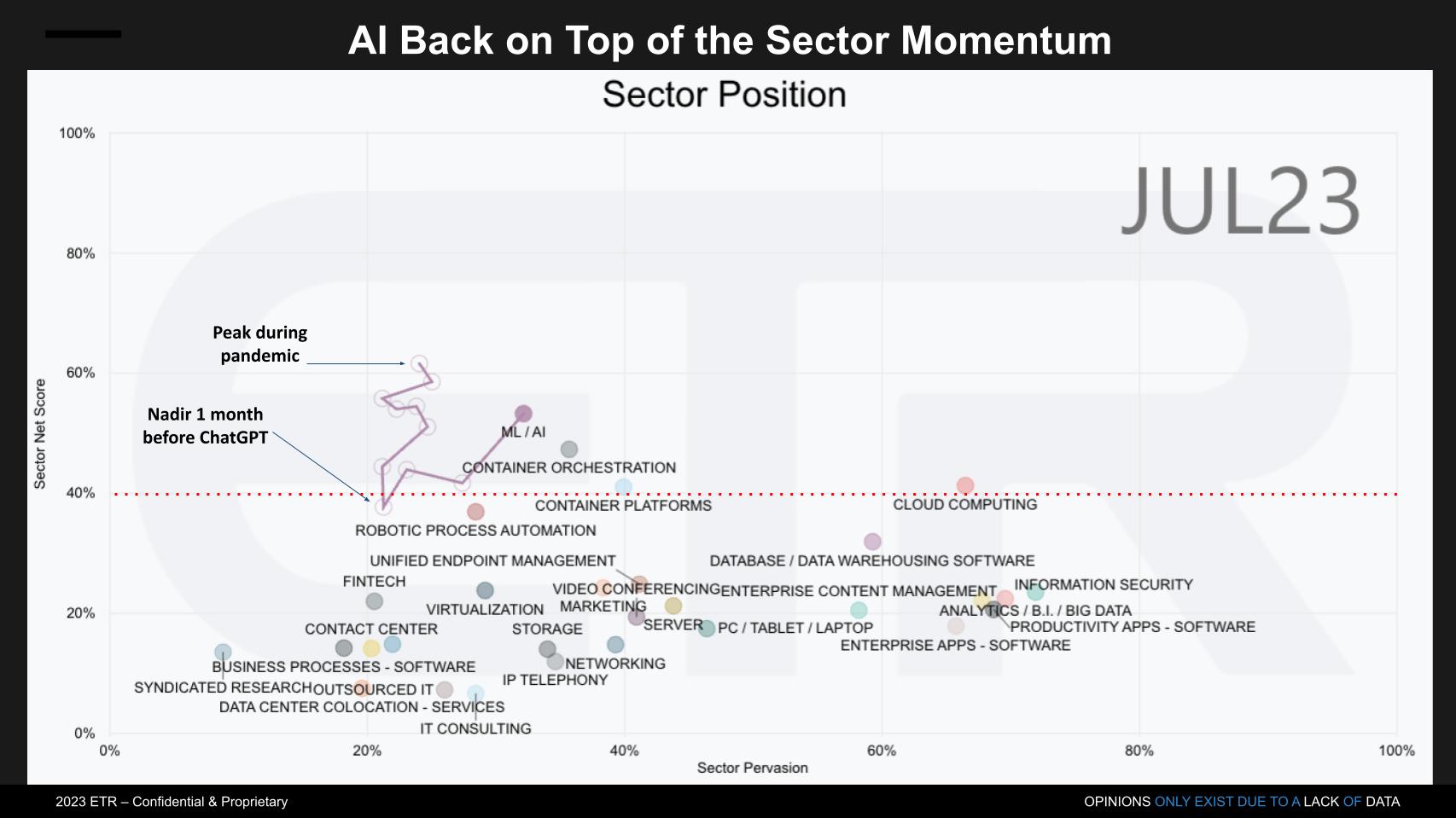
The graphic above depicts spending profiles across all the sectors in the ETR taxonomy. The vertical axis is Net Score or spending momentum and is a measure of the net percent of customers in the survey that are accelerating spend in a sector. The horizontal axis is Pervasion in the data and is a measure of the N’s in a specific sector divided by the total survey N of approximately 1,700 IT decision makers representing $776B in tech spending. The red dotted line is an indicator of highly elevated spending velocity.
Throughout the pandemic as our research indicated, AI, along with cloud migration, containers and RPA were consistently the top four sectors in terms of spending momentum. Momentum across all sectors generally decelerated in 2022 into 2023 including AI. The squiggly line above shows the trajectory of AI’s Net Score over that period, which bottomed one month prior to ChatGPT’s announcement. Since that time it has been up and to the right, gaining velocity and taking more share of wallet.
Q. Jeff, given the hype around generative AI and ChatGPT, how do you envision separating genuine progress and applications from inflated promises and the over expectations in the market?
It’s going to be huge man. I think it’s going to be a rocket. That little line that we see there is just going to continue to zoom. I think after Watson beat “Jeopardy!” it captured the world’s imagination and tens of billions of dollars went into the field of AI. It’s going to be 100 times that big, and the utility of LLMs is phenomenal. It’s overestimated, but it’s still huge. So, I think it’s straight up from here.
Q. Why do you think that IBM Watson didn’t just run the table on this whole space?
I think people over imagined all of its utility. I think that original algorithms, the stack, was really tailored to actually beat the game “Jeopardy!.” I remember being in Singapore and somebody was telling me they wanted to use those algorithms to do fluid modeling for tsunamis over the surface of the Singapore landmass. I’m like, “That is the wrong use for that.” So, I think those original algorithms had a certain set of utility that are more narrow, and I think the value of LLMs and the range of utility is going to be spectacular, but probably half as big as people actually think.
Further Breaking Down AI’s Spending Momentum
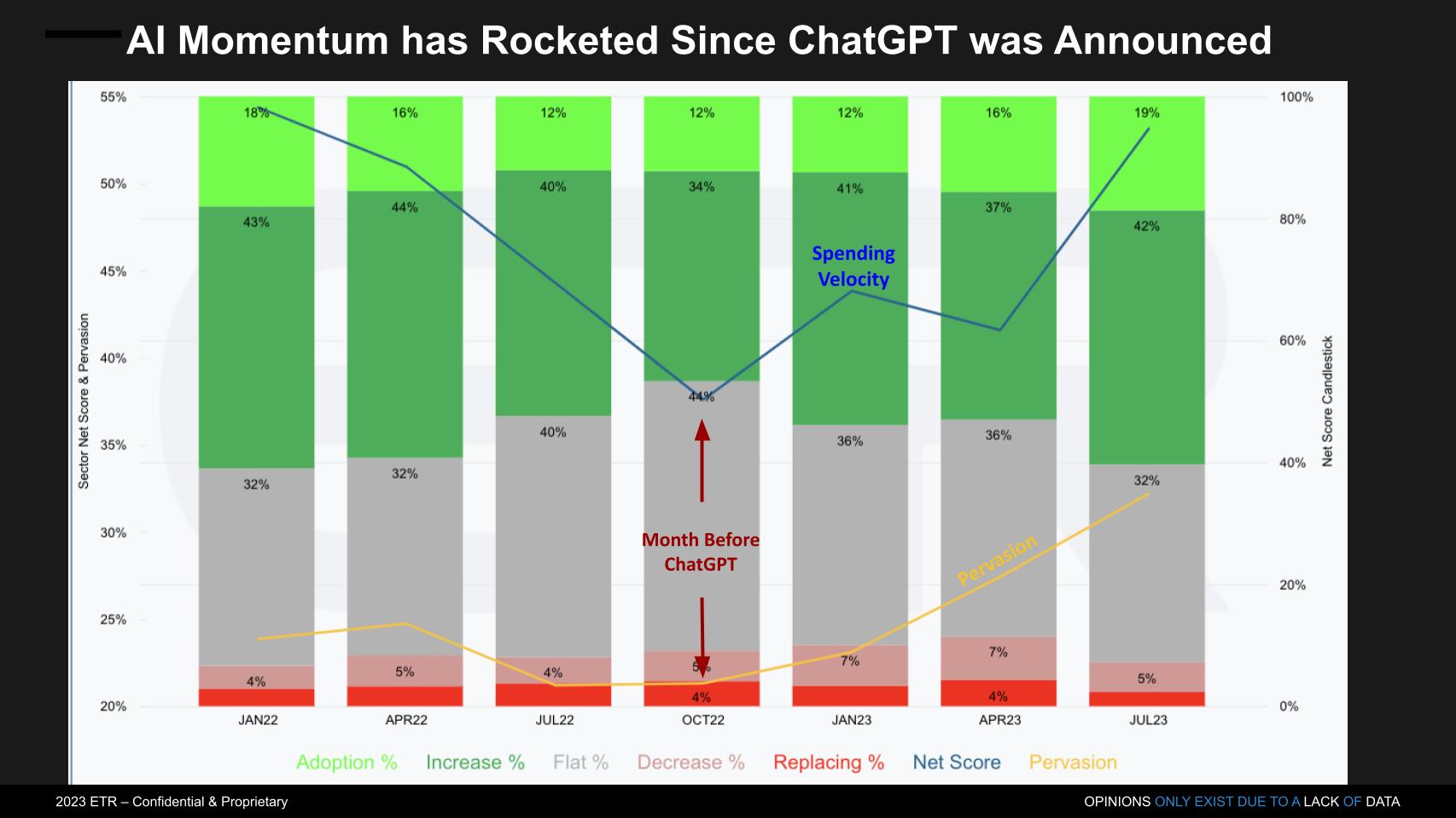
The graphic above zooms into the Net Score granularity within the AI sector. The colors break down the percent of customers in the AI sector as follows:
- Lime green is new customer adds for AI platforms.
- Forest green is the percent of customers spending 6% or more relative to last year.
- The gray is flat spending – i.e. plus or minus 5%.
- The pink spending is down 6% or worse.
- The bright red, which is basically zero, represents is churn.
When you subtract the reds from the greens you get Net Score, which is the net percentage of customers that are spending more on a specific technology. Net Score is shown above as that soaring blue line. The yellow line represents pervasiveness of AI in the survey and is calculated by taking the N in the AI sector divided by the N in all sectors (Survey N = ~1,700).
Note the steep rise in both Net Score and Pervasion since October 2022, one month before ChatGPT was announced.
Q. Jeff, in terms of technical advancements, how do you see the development of AI and generative AI, moving beyond supervised learning and today’s LLMs? What do you think is most promising in terms of areas of research in this regard and potential impacts that they’ll have on society?
I think the really big thing that’s happening is integrating diverse data. The fact that I can go to ChatGPT and ask for a board agenda and then have it reduce it to a rhyme and then reduce that to a haiku is because it’s been trained over such diverse data. When researchers in Africa found termite mounds that have natural climate control, they started working with people building energy-efficient skyscrapers, and applying new innovations breaking out of that [finding]. There are so many new innovations and breakthroughs coming from better connected and integration of diverse data. And we’re going to see this in a lot of different texts, graph databases, of course what we’ve seen, LLMs, vector databases, traditional machine learning, entity resolution, integrating diverse data about people. But it’s this collection of technologies to integrate diverse data that I think’s really, man, it’s going to accelerate what’s happening in personalized medicine, improvements to climate change.
[Jeff Jonas shares some examples of how AI technical advancements will impact society].
Q. You just mentioned different types of databases like vector and graph; and different data types. When you think about graph for example, graph’s interesting because you get this expressiveness with a graph database, but the way in which you query the data is still complicated. How do you see the way in which we interact with data changing, for example where you can get the expressiveness of a graph database with much simpler and flexible querying?
I think the way humans interface with computers is about to radically change with these LLMs. In my particular case where you’ve got an entity resolution algorithm that’s got JSON in to JSON out, now you can literally do conversational entity resolution. You’ll say, “Hey, can you load a record that looks like this?” It’ll automatically load it. Why do these two records come together, and you can get the answer in plain English. Imagine, and so you package that type of qualitative human language and you put that on top of graph databases, on top of entity resolution, on top of anything, you’re not going to do Jeff Tab Tab, Jonas Tab, June Tab, 22nd. You’re going to literally just say it or type it. And so, how we interface with computers is going to change. By the way, I’ve been thinking about this. You know how sometimes you want to change the behavior of some software, so you’re having to look in settings and then look through the tabs.
You’re just looking for the one switch, okay? That’s going away. We’re literally going to be just like, “Can you make it not do that anymore?” And it goes, “Yeah, I got that for you.”
[Jeff Jonas talks about changes in the way humans will interface with computers in the near future].
The AI Race is on…Notable Shifts in Leadership Since ChatGPT’s Unveiling
Microsoft cuts the line and OpenAI storms the castle…
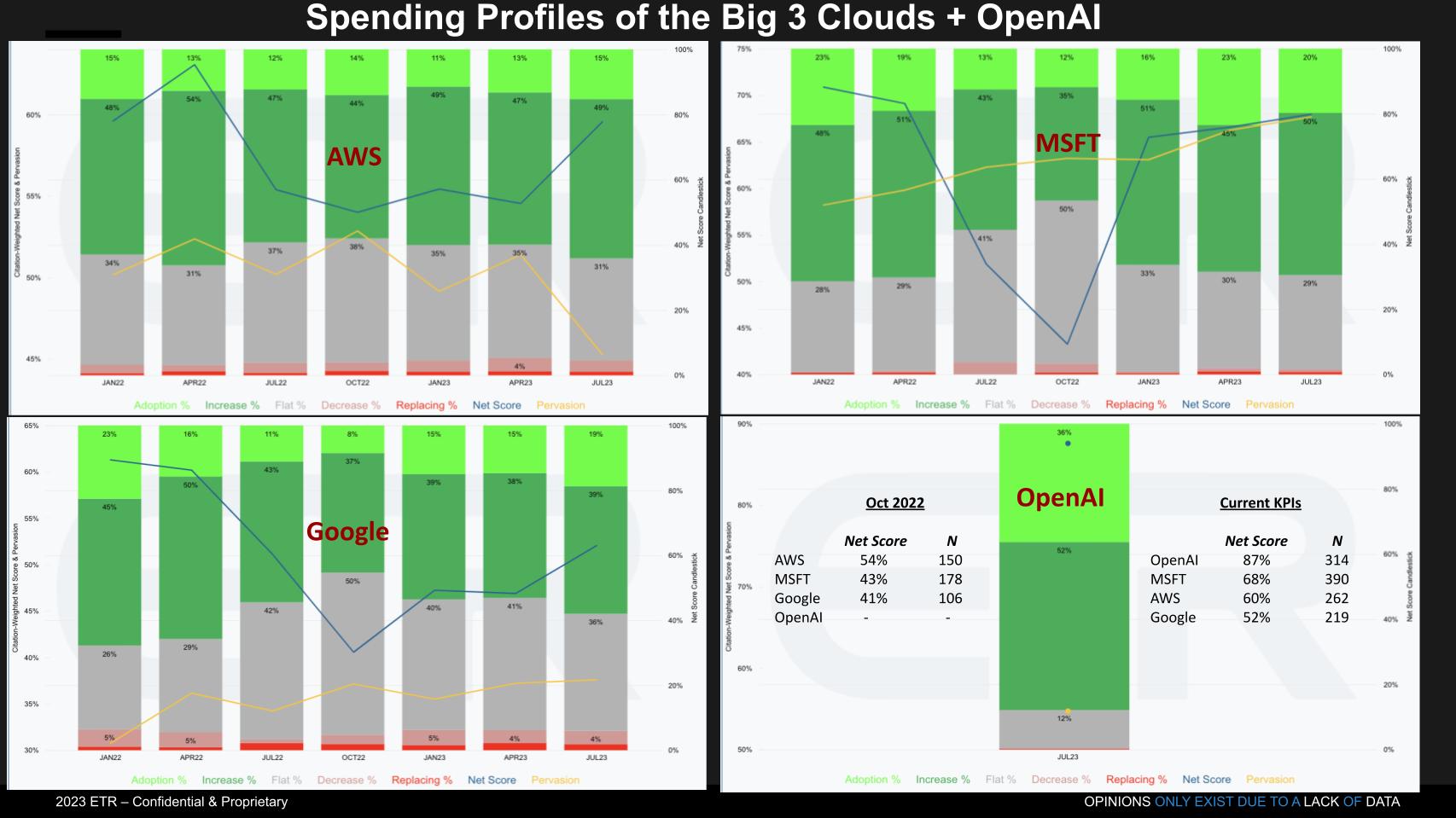
The big three cloud players have consistently shown momentum in AI. Well before the announcement of ChatGPT, AWS had traction with SageMaker, Microsoft’s relationship with Databricks and Google’s efforts to promote its data strategy combining its ML/AI with BigQuery.
The graphic above shows the Net Score granularity for AWS, Microsoft, Google and OpenAI, which only has one quarter of data in the ETR database given its recent ascendency. Some notable highlights in the data are:
- Each of the AI platforms from the Big 3 cloud players bottomed in October 2022, one month prior to ChatGPT’s introduction.
- Prior to ChatGPT, AWS had the #1 position by a wide margin in terms of spending momentum followed by Microsoft and Google.
- Since the announcement of ChatGPT:
- All three hyperscalers have seen meaningful and rapid increases in Net Score (spending velocity) boosted by announcements from AWS (Bedrock, etc.), Google (Bard, etc.) and Microsoft with OpenAI.
- OpenAI has, by far, the highest Net Score, is #2 in N mentions and has 20% more N mentions than AWS in the current survey.
- Microsoft, through its investment in and relationship to OpenAI has “cut the line” and overtaken AWS in terms of spending velocity. It has also extended its lead in N mentions relative to AWS from 19% more prior to ChatGPT expanding to nearly 50% more N’s in the latest survey.
- All of the hyperscaler platforms have seen a meaningful uptick in survey N’s for their AI platforms, however AWS as seen by the yellow lines above, has seen a relative drop in its pervasiveness in the survey
The bottom line is the position of the leaders has changed as a direct result of the introduction of ChatGPT. While this shift is by no mean permanent it is changing buyer and vendor behavior. Buyers are experimenting with OpenAI tools and vendors are scrambling to close the mindshare gap.
Q. Jeff, as you look at OpenAI’s GPT-3 and now GPT-4, a lot of questions surface about responsible AI, the potential misuse of powerful AI models, particularly as they become more widely available. How do you think organizations should be thinking about this tension between broad-based access and potential misuse, especially as these models become more capable?
Well, you definitely want to be careful not submitting data that’s going to live in somebody else’s logs and then be used for training, and now you’ve got some of your proprietary data in there. So, there needs to be careful work on that, and there’ll be more remedies for more organizations to run their own local models or have their data protected when they’re using public models. It’s going to be very interesting to see what data was used to train what and what entitlements did people have to use for that data? Are they using data that they had the rights to use? And I think that’s going to be really interesting. There will be some benefits to those that have a wider range of data. When I asked ChatGPT about who I am, it confuses me with the “Ironman” movie ’cause I do Ironman Triathlons. I mean it’s damn convincing, like it tells me I met with John Favreau, the filmmaker, in Vegas in a think tank. And I’m like, “Did I? I sit in think tanks and I meet filmmakers, did I meet him?” But I did some more research and called some people to see if these claims about me were true, and it’s not.
Complaining About Hallucinations with Generative Models is a Sign You’re Using them the Wrong Way…
But here’s the thing about hallucinations. If you’re complaining about these things having hallucinations you’re already using ’em the wrong way. They’re not designed for truth, like literally they’re qualitative not quantitative. My litmus test is if you were to ask the generative AI tomorrow the same question and if you get a different answer, if that’s a problem, you’re already using it the wrong way. So, qualitative is its best use, not truths.
Q. In a fireside chat Jensen Huang held with Ilya Sutskever, the founder of OpenAI, Ilya said exactly what you’re saying, that ChatGPT wasn’t designed to be a source of truth…that it wasn’t designed with guardrails against so-called hallucinations. But he implied that those things will be added over time. Don’t you think ChatGPT will evolve to address these issues over time?
It’s generative though. In its bones it’s generative. I think that a definitive paper on this was written by the WolframAlpha guy. He wrote like a 42-page paper on it, and I really love that paper ’cause it kind of describes how it works. But it basically already commits to a bunch of words, on Thursday they went to the beach to, then it’s like swim, sunbathe, and it just rolls the dice to pick the next word. And then it goes, “Okay, I committed to sunbathe, now what?” That’s what generative does, and it’s phenomenal. But you can’t use that for things where you need the same answer tomorrow. That’s not the way to use it. And it doesn’t have any source. You can’t ask it about where did it get the information. When I ask it about this Jeff Jonas-“Ironman” conflation, it finds quotes that I said in “WIRED” magazine or a blog post that I never said.
It gives you links that aren’t true. It’s sourceless, you can’t get attribution for it. And so, again, I sound like I’m whining, but it’s phenomenal. It’s going to do all kinds of things. But if you are wishing to get the same answer tomorrow and you need it explainable then it’s not going to be this LLM type of technology. It’ll be something else. I mean…what we’re doing, we have an AI we’ve been working on now for a long time that does entity resolution, figures out who’s who, realtime self-learning. We get the same answer tomorrow, and it’s explainable. So, it’s going to get inserted. Things like WolframAlpha gets inserted into ChatGPT so it can do math. I think Entity Engine, Senzing, or whatever, will be used to call ’em antipsychotics into these LLMs.
So, we’ll see things maybe integrated with them and then these LLMs will put flowery words around it. But don’t underestimate what else is coming. I’m just saying LLMs themselves that lose attribution, they don’t know really the source, are only going to do so many things by themselves.
More Competition than Just the Big Cloud Players
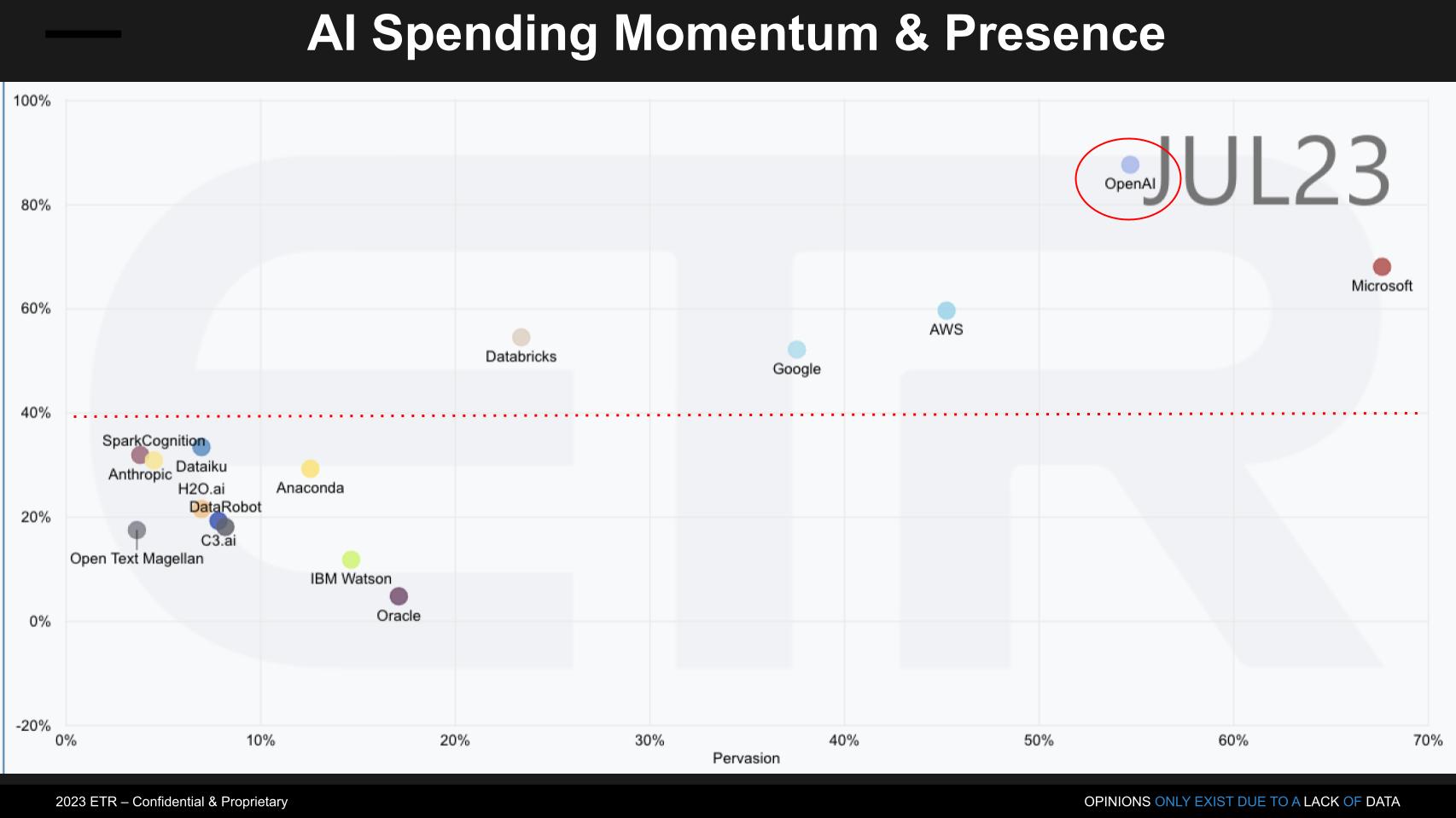
While cloud players dominate the conversation along with OpenAI, several other companies have been in market for quite some time. And VC funding is pouring into AI. The graphic above shows Net Score or spending momentum on the vertical axis and pervasiveness in the data set on the horizontal axis – informed by the N’s in the survey for each platform.
OpenAI has burst onto the scene as we’ve previously reported. OpenAI along with the Big 3 hyperscalers stand alone above the 40% elevated line along with Databricks. Databricks made a big move with the acquisition of MosaicML. At Snowflake Summit we saw Snowflake announce a partnership with Nvidia, basically betting on the Nvidia gen AI stack and containerizing it in Snowpark as an LLM offering. Bringing AI to the data. At the time we felt this was a move by Snowflake to leapfrog Databricks’ supervised learning ML/AI tool chain with an unsupervised play. But the MosaicML acquisition and Databricks’ announcements suggest to us that Databricks’ is willing to disrupt itself.
Snowflake doesn’t yet show up in the ML/AI sector of the ETR data set so we’ll be watching to see if it does in the future. Other notable players include Anthropic, Dataiku, H2O.ai, DataRobot, C3.ai, Hugging Face (not shown) and of course the big legacy players, IBM and Oracle. But many more companies are playing in this field and this is a small sample of the activity happening in the space with lots of opportunities to participate. But things are moving fast.
Q. Jeff, with several companies and organizations working on similar AI technologies how do you think firms can differentiate their AI products or solutions from others in the market? What’s going to be that unique value prop that firms will offer that’s going to set them apart?
Man, that is going to be tough. I’m speculating right now that there are companies out there that are getting term sheets, but they’re going to be out of business before they get their first round. Like that’s how fast it’s moving, you know? Warren Buffett calls it the moat. It’s going to be hard to have moats in a lot of cases. You’ve got to build things that everybody else doesn’t have. Folks that think you can take three publicly available things, wrap ’em together and call it unique. It’s not unique. So, if you want to have something unique you have to have, you better have real work. You have to have something that’s really different, and that’s hard for others to replicate. So, that is the big question. And I’ll tell you the VCs, as an LP, I am an LP in four funds, you got to be really careful what you fund ’cause you have to ask how are they going to be different?
There’s a lot of mystery around that, especially, you can add an LLM. Anybody can add an LLM to anything right now, so you better have something different that’s not just the LLM. And by the way, lastly, you still better add an LLM onto your widget as soon as you can or you’re not going to be very interesting. Because if a company has money to spend they’re going to spend it on things that have AI and LLMs related to them versus something else ’cause they’ve got to report it up to the leadership who’s going to report it up to the board because the board’s asking the leadership, “How are we investing in this?” So, you got to get in the wave.
[Jeff Jonas talks about the challenges of differentiating in AI and how to ride the wave].
Q. Don’t you think data is going to be that differentiator? Won’t that ultimately determine and define the moat?
I think it’s going to make a big difference. When I ask Bing about who I am, because they have, maybe it’s because they have LinkedIn, but its quality of understanding is so much better. I do think he who has the most knowledge and can harness it is going to have the best advantage. And then how is that going to be liberated, that data, so that others can build those into their systems? And what’s the pedigree of that data? It’s going to be a very interesting world coming. It’s exciting.
Q. Furrier and I talk about this a lot on our CUBE pod…trying to compare with other waves. They’re never identical and past is not always prologue in tech, but you think about the Internet it benefited a lot of incumbents. And yeah, there was a lot of disruption too, but everybody was able to take advantage of it. How do you see this wave relative to other waves like PCs, the Internet, cloud, mobile, etc.
I think this wave’s going to be 100 times bigger than the Watson wave. Maybe 1,000 times bigger. There are so many exciting ways to integrate LLMs into systems to create better experiences for organizations using technology. Yeah, that’s it man. This could be, it’s going to show up everywhere by the way, and you don’t even have to do it yourself. I mean, it’s going to be in your office. I mean, it’s going to be in the apps you’re using at the office. It’s going to be in these tools you use. It’s just being integrated left and right, and the world’s going to become more conversational. I think, a weird thing is like cursive, they don’t teach cursive anymore in school. And you have to wonder when things become really natural language oriented if, at what point do keyboards go away?
[Jeff Jonas talks about the magnitude of this wave compared to other innovations].
Q. You referenced this earlier that you’ve got to jump on board and ride the wave. You have to apply LLMs like now, yesterday, months ago. So, how should leaders think about investing in AI? What would your advice be?
Well, my first advice on that…there’s a lot of people labeling things AI, and it’s a bit of a stretch. So, one thing you want to do is probably find something that is legitimate, you want to make sure that it’s going to work within your compliance and having repeatable answers. You want to use it in ways that are going to be responsible. You’re going to have to be able to answer to the decisions that you’re making. I think if LLMs get used qualitatively, to package up and put the words around the messaging to the customer or around the advice, it’s not the actual core of the advice. I think it’s probably a bit safer. And I think a lot of organizations are going to get their AI through partners that are specializing in AI. I mean, I’m trying to outsource entropy.
The second law of thermodynamics, the world’s trying to break into small pieces, spread out and cool off. And you have to be careful where you spend your energy. We spend our energy, the food we eat in organizations, to hold things together. No one’s out there with an army of people doing AI on spell check and grammar check or you plug in an API. That’s the kind of thing I’m trying to do for entity resolution, who’s who. And I think organizations are going to find lots of technology components that have AIs built in them that they can integrate into the workflows that they have or the products that they’re building for the market.
[Jeff Jonas gives his advice for investing in and deploying AI].
Entropy is Winning
Q. You mentioned entropy. The second law of thermodynamics, doesn’t it say entropy increases over time?
Well, if you can buy something and plug it in, like most organizations aren’t building their own credit card settlement. You’d use Stripe. Most organizations aren’t building their own mobile comms, they would use a Twilio. So, I definitely think you try to outsource the entropy and have somebody else’s specialist slug it in. Hey, this thing about anomalies though in big data, things that are rare, like one in a million, happen a million times a day. So, rare doesn’t always mean interesting. And by the way, entropy might be winning. I don’t know, as I think about it (laughs) these LLMs, they’re creating more data, and the more data, I blogged about my thing with the Ironman and then LLMs are going to end up reading that and then they’re going to insert it into their knowledge base. We’re going to need a clear demarcation line between data that was generated by humans and actual sources versus data just purely generated.
I used to think in this entity business you’re trying to figure out who’s who to, like hey, they’re all the same people. Decades ago I’m like, “Well, you won’t need to do this for very long because there’ll just be common keys. Everyone shares the key.” There are now more keys than ever. You have more handles about you, entropy’s winning. The universe is having its way with us.
Q. Last question, if you had to start a company today, how would you go about thinking about what to start?
Well, I would first say that you want to build a capital efficient company. This idea of just throwing more money on and going with vanity metrics, how many people you have, how much money you’ve raised, and growth at all cost, I think is just basically out the window. I just don’t think that’s the future. I think if you’re going to start a company you got to figure out unit economics, and you have to be able to make money along the way and early. And I see some companies that are really good product people, marketing people, and they figure out how to market anything. And you see some companies have really good engineering technology but they don’t know how to market it. And it’s really the pairing of the two. If you can’t figure, you can have an A tech and not a great go-to market and then you’re just going to be wha-wha. So, anyway, capital efficiency, and you probably have to be as good at marketing as you are in your tech.
[Jeff Jonas riffs on how he would go about starting a new company in today’s dynamic market].
Jeff Jonas has been working on hard problems in data for decades. His counsel is sought after by governments, investors and customers around the world. He’s not only a tech athlete, he’s an elite and accomplished triathlete and a great friend of theCUBE. We’re grateful for his many contributions over the years and to this program.
Keep in Touch
Many thanks to Alex Myerson and Ken Shifman on production, podcasts and media workflows for Breaking Analysis. Special thanks to Kristen Martin and Cheryl Knight who help us keep our community informed and get the word out. And to Rob Hof, our EiC at SiliconANGLE.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com | DM @dvellante on Twitter | Comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail.
Watch the full video analysis:
Note: ETR is a separate company from Wikibon and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai.
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of Wikibon. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.

