With George Gilbert
Uber has one of the most amazing business models ever created. The company’s mission is underpinned by technology that helps people go anywhere and get anything. The results have been stunning. In just over a decade, Uber has become a firm with more than $30 billion in annual revenue, an annual bookings run rate of $126B and a market capitalization near $90 billion today.
Moreover, the company’s productivity metrics are 3-5 times greater than what you’d find at a typical technology company when, for example, measured by revenue per employee. In our view, Uber’s technology stack represents the future of enterprise data apps where organizations will essentially create real time digital twins of their businesses and in doing so, deliver enormous customer value.
In this Breaking Analysis, we introduce you to one of the architects behind Uber’s groundbreaking fulfillment platform. We’ll explore their objectives, the challenges they had to overcome, how Uber has done it and why we believe their platform is a harbinger for the future.
The Technical Team Behind Uber’s Fulfillment Platform
Shown here are some of the technical team members behind Uber’s fulfillment platform. These individuals went on a two year journey to create one of the most loved applications in the world today.

It was our pleasure to welcome Uday Kiran Medisetty, Distinguished Engineer at Uber. He has led, bootstrapped, and scaled major real-time platform initiatives in his time at Uber and agreed to share how the team actually accomplished this impressive feat of software and networking engineering.
[Watch this clip of Uday describing his background and role at Uber].
Uber as the Future of Enterprise Data Apps
Back in March, we introduced this idea of Uber as an instructive example of the future of enterprise data apps. We put for the premise that the future of digital business applications will manifest itself as digital twins that represents people, places and things of a business operation. We said that increasingly, business logic will be embedded into data on which applications will be built from a set of coherent data elements.
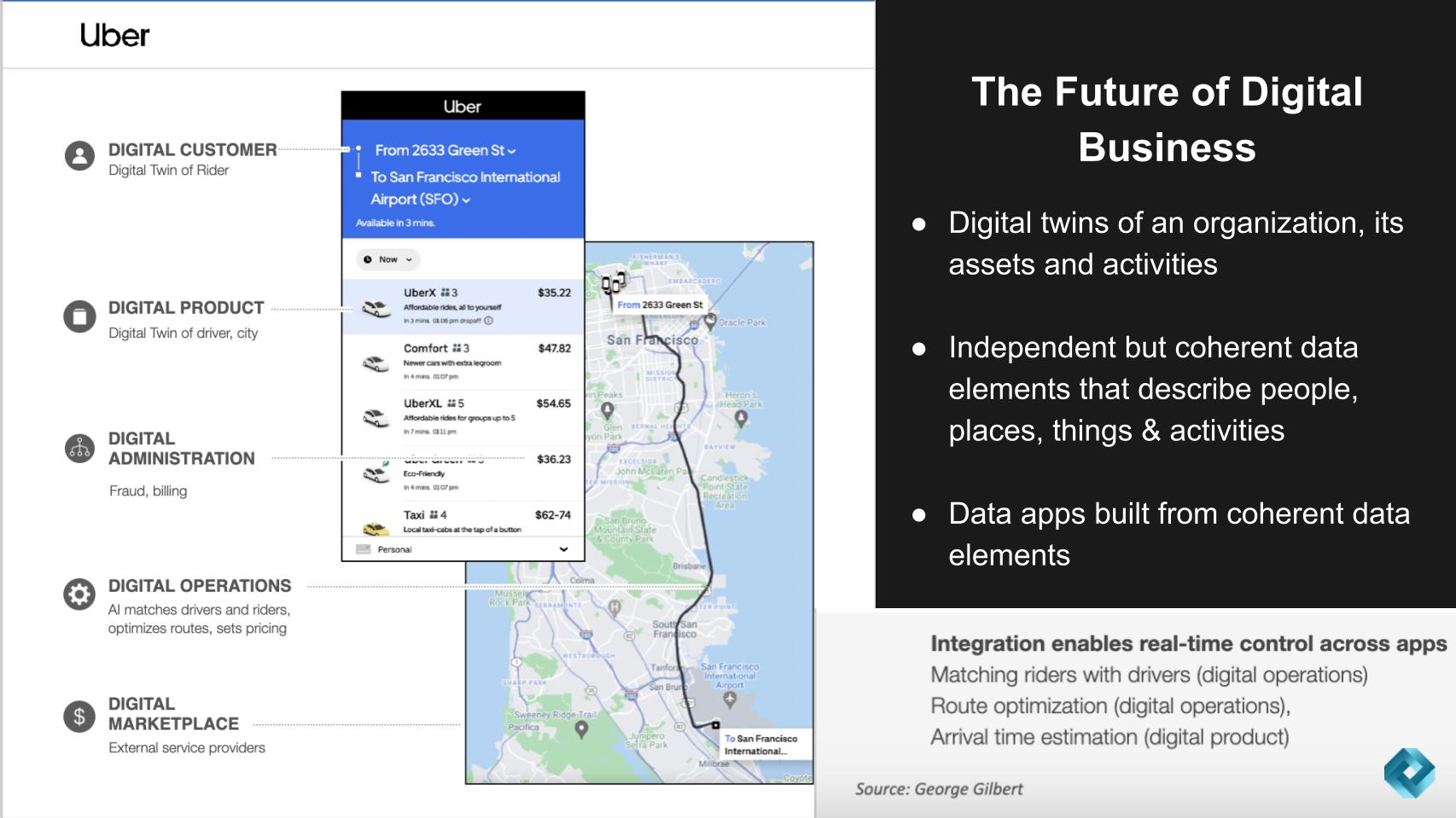
The Evolution of Enterprise Applications
When we follow the progression of enterprise applications throughout history, it’s useful to share some examples of inflection points on the journey and where we are today.
The graphic below describes the history in simple terms, starting with enterprise 1.0 which focused on departmental or back office automation. The orange represents the ERP movement where a company like Ford integrated all its financials, supply chain and other internal resources into a coherent set of data and activities that drove productivity. Then Web 2.0 for the enterprise. And here we’re talking about using data and machine intelligence in a custom platform to manage an internal value chain using modern techniques. We use Amazon.com’s retail operation (not AWS) as the example.
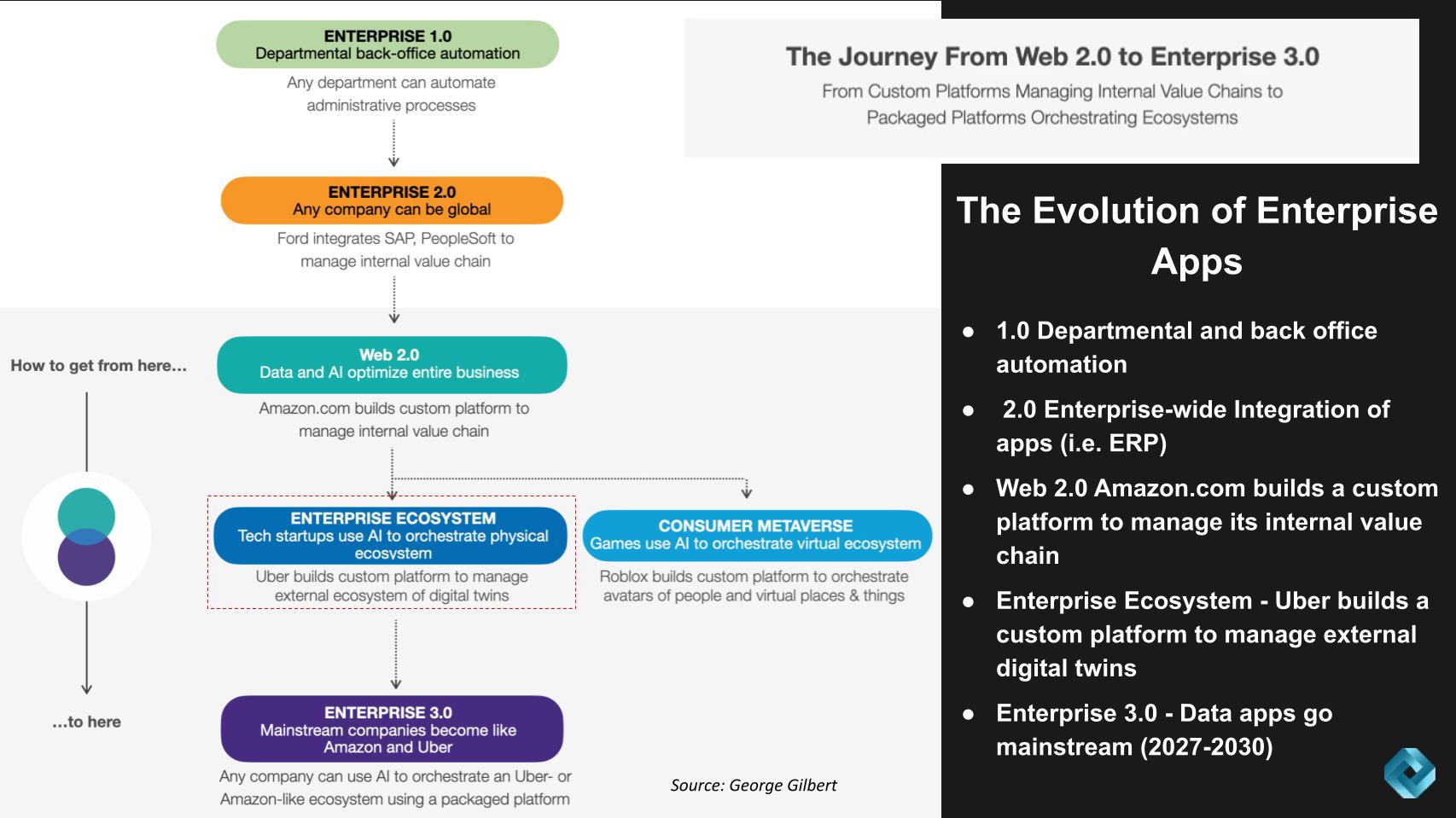
Uber Represents a Major Milestone in Application Experiences
Highlighted by the red dotted line, we show “Enterprise Ecosystem” apps which is where we place Uber. Uber is one of the first, if not the first, to build a custom platform to manage an external ecosystem. To the right we show the Consumer Metaverse represented in the gaming industry.
Our fundamental premise is that what Uber has built represents what eventually mainstream companies are going to be able to buy. That is packaged apps that use AI to orchestrate an Uber-like ecosystem experience with off-the-shelf software and cloud services. Because very few organizations possess a team like Uber’s, we believe an off-the-shelf capability that can be easily deployed by organizations will be in high demand as real-time data apps become mainstream platforms.
With this as background, we dove into a series of Q&A with Uday that we’ll summarize below with our questions and Uday’s response in the pull quotes.
Q1. Uday, can you explain in layman’s terms how the architecture of an application orchestrating an entire ecosystem differs significantly from the traditional model of packaged apps managing repeatable processes?
One of the fascinating things about building any platforms for Uber is how we need to interconnect what’s happening in the real world to build large scale, real-time applications that can orchestrate all of this at scale. There is a real person waiting in the real world to get a response from our application whether they can continue with the next step or not. If you think about our scale, with, for example, the last FIFA World Cup, we had 1.6 million concurrent consumers interacting with our platform at that point in time. This includes riders, eaters, merchants, drivers, couriers, and all of these different entities. They are trying to do things in the real world and our applications has to be real time, everything needs to be consistent, it needs to be performant, and on top of all of this, we need to be cost effective at scale.
Because if we are not performant, if you’re not leveraging the right set of resources, then we can explode our overall cost of managing the infrastructure. So these are all some unique challenges in building an Uber-like application. And we can go into more details on various aspects both at breadth and also in depth.
Our Takeaway:
Uber’s application is a complex orchestration of real-time, large-scale activities, demanding immediate, reliable, and efficient responses to various user interactions. Performance and cost-effectiveness are pivotal to handle its massive user base without inflating infrastructure costs. We believe this represents a radical shift and a monumental transformation from the application’s perspective, especially considering our common experiences within the world of enterprise tech.
Q2. Uday, based on a series of blog posts that you and the team authored, we know you ran into limits back in 2014 with the existing architecture. What limitations did the 2014 architecture pose to Uber’s mission at scale, prompting the need for an architectural rewrite as you mentioned in your blogs? Particularly, could you elaborate on the trade-off you discussed—optimizing for availability over latency and consistency? Why was this a problem and how did Uber address this issue?
If you think back to 2014 and what was the most production ready databases that were available at that point, we could not have used traditional SQL-like systems because of the scale that we had even at that point in time. The only option we had, which provided us some sort of scalable realtime databases was no-SQL kind of systems. So we were leveraging Cassandra and the entire application that drives the state of the online orders, the state of the driver sessions, all of the jobs, all of the waypoints, all of that was stored on in Cassandra. And over the last eight years we have seen [a big change in] the kind of fulfillment-use cases that we need to build for.
So whatever assumptions that we made in our core data models and what kind of entities we can interact has completely changed. So we had to, if not anything else, change our application just for that reason. The second, because the entire application was designed with availability as the main requirement, and latency was more of a best effort and consistency was more of a best effort mechanism, whenever things went wrong, it made it really hard to debug. For example, we don’t want a scenario where if you request a ride, two drivers show up at your pickup point, because the system could not reconcile whether this trip was already assigned to a particular driver or it wasn’t assigned to anyone. And those were real problems that would happen if we didn’t have a consistent system.
So there were several problems at the infrastructure layer at that point. One is consistency that I mentioned already, and because we didn’t have any atomicity, we had to make sure the system automatically reconciles and patches the data when things go out of sync based on what we expect the data to be. There was a lot of scalability issues. Because we were getting to a best effort consistency, we were using at the application layer some sort of hashing. And what we would do is [try to] get all of the updates for a given user routed to a same instance and have a queue in that instance so that even if a database is not providing consistency, we have a queue of updates.
So we made sure there’s only one update at any point in time. That works when you have updates only in two entities, so then at least you can do application level orchestration to ensure they might eventually get in sync, but it doesn’t scale beyond that. And because you are using hashing we could not scale our cluster beyond the vertical limit. And that also inhibited our scale challenges, especially for large cities that we want to handle, we couldn’t go beyond a certain scale. So these were the key infrastructure problems that we had to fundamentally fix so that we can set ourselves up for the next decade or two.
Our Takeaway:
The architecture of Uber’s app in 2014, while suitable for its time, faced substantial challenges as the company grew and its use cases evolved. The architecture faced issues around consistency, lack of atomicity, hashing collisions that limited scalability and the like. These, coupled with changing business requirements, highlighted the necessity for an architectural rewrite to ensure the platform’s sustainability and success in the decades to come.
Q3. Uday, considering Uber’s expansion beyond just drivers and riders to support new verticals and businesses, could you discuss how improvements in database capabilities have affected your approach to consistency and latency? Furthermore, could you elaborate on how you’ve generalized the platform to accommodate these new business ventures?
So that’s a great question. You know, one of the things we had to make sure was as the kind of entities change within our system, as we have to build new fulfillment flows, we need to build a modular and leverageable system at the application level. At the end of the day, we want the engineers building core applications and core fulfillment flows abstracted away from all of the underlying complexities around infrastructure, scale, provisioning, latency, consistency. They should get all of this for free, and they don’t need to think about it. When they build something, they get the right experience out of the box. So what we had to do was, at our programming layer, we had a modular architecture where every entity, for example, let’s say there is an order…there is an order representation, there’s a merchant, there’s a user or an organization representation, and we can store these objects as individual tables and we can store the relationships between them as another table that stores the relationships between these objects.
So whenever new objects get into the system and whenever we need to introduce new relationships, they are stored transactionally within our system. We use the core database, you can think of it as a transactional key value store. At the database layer, we still only store the key columns that we need and rest of the data is stored as a serialized blob so that we don’t have to continuously update the database. Anytime we add new attributes for a merchant or for a user, we want to [minimize] operational overhead. But at the high level, every object is a table and then every relationship is a row in another table, and then whenever new objects or relationships get introduced, they are transactionally committed.
Our Takeaway: A Semantic Layer Built in the Database
What Uday describes above is an implementation of a semantic layer within the database. Uber has developed a flexible and modular application architecture that supports the introduction and management of new business verticals and entities, freeing engineers from infrastructure and data complexities. This architecture enables the smooth integration of new objects or relationships, maintained transactionally within their system, allowing for scalable and efficient system growth.
The Critical Aspects of Uber’s new Architecture
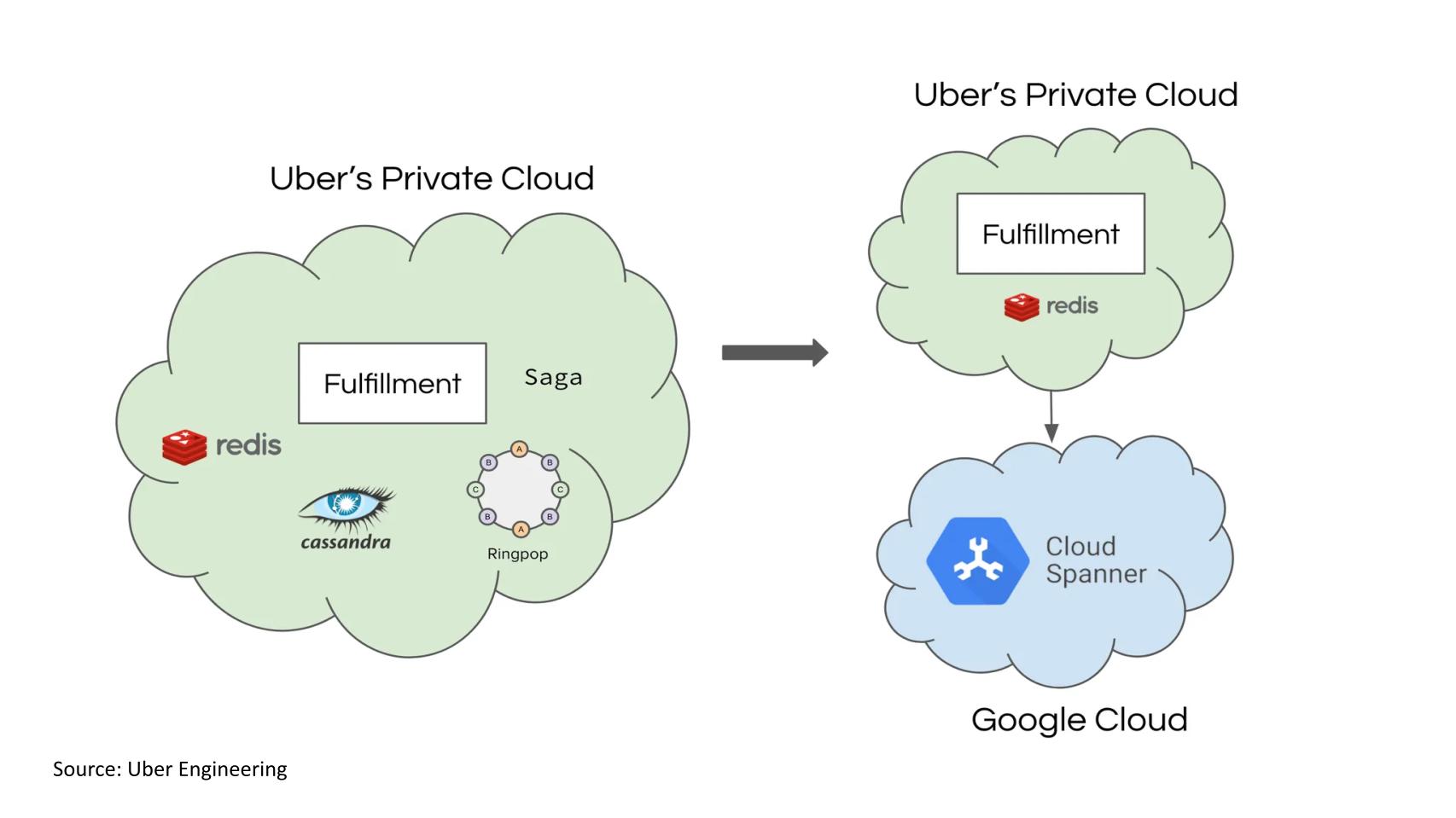
Above we show a chart here from Google Engineering. One objective in our research is to understand how the new architecture differs from the previous system and how Uber manages the mapping between the physical world (people, places and things) and the logical user experience. The way we understand this graphic is the Green is the application layer (intermixed with the data platforms) on left hand side. The right hand side represents the new architecture and shows that Uber has separated the application services (at the top in green) from the data management below, where Google Cloud Spanner comes in to play.
Q4. Uday, could you help us grasp the key aspects and principles of your new architecture, particularly in contrast with your previous one? Could you explain how this new architecture differs from the previous one and what these changes mean to your business?
We went through some of the details of the previous architecture earlier. Like the core data was stored in Cassandra and because we want to have low-latency reads, we had a Redis cache as a backup whenever Cassandra fails, or whenever we want some low-latency reads and we went through Ringpop, which is the application layer shard management, so that the request gets routed to the instance we need. And there was one pattern I didn’t mention, which was on Saga pattern, which was a paper from a few decades ago. Ultimately there was a point in time where the kind of transactions that we had to build evolved from just two objects. Imagine, for example a case where we want to have a batch offer, which means a single driver could accept multiple trips at the same time or not.
Now, you don’t have a one-t0-one association, you have a single driver, I have maybe two trips, four trips, five trips, and you have some other object that is establishing this association. Now if we need to create a transaction across all of these objects, we tried using Saga as a pattern, extending our application layer, transaction coordination. But again, it became even more complex because if things go wrong, we have to also write compensating actions. So that system is always in a state where they can proceed. We don’t want users to get stuck and not get new trips. So in the new architecture, the key foundations we mentioned, one was around strong consistency and linear scalability. So the new SQL kind of databases provide that.
And we went through an exhaustive evaluation in 2018 across multiple choices. And at that point in time we picked [Google] Spanner as the option. We moved all of the transaction coordination and scalability concerns to the database layer, and at the application layer, we focus on building the right programming model for building new fulfillment flows. And the core transactional data is stored in Spanner. We limit the number of RPCs that we go to from our on-prem data centers to Google Cloud because it’s a latency sensitive operation, right? And we don’t want to have a lot of chatter between these two worlds. And we have an on-prem cache which will still provide you point in time snapshot reads across multiple entities so that they’re consistent with each other.
So for most use cases, they can read from the cache and spanner is only used if I want strong reads for a particular object. And if I want cache reads across multiple objects, I go to my cache. If I want to search across multiple objects, then we have our own search system which is indexed on specific properties that we need. So that if I want to get all of the nearby orders that are currently not assigned to anyone, we can do that low latency search at scale. And obviously we also emit Kafka events within the Uber stack, so then we can build all sorts of near real time or OLAP applications and then it’s also virtual raw tables, then you can build more derived tables using Spark jobs…But all of those things are happening within Uber’s infrastructure and we use Spanner for strong reads and core transactions that we want to commit across all of the entities and establishing those relationships that I mentioned.
Here’s our summary of Uber’s new architecture:
Uber’s new architecture addressed the complexity of its previous system emphasizing three key changes:
- Transition to a consistent and scalable database: The old architecture relied heavily on Cassandra for storing core data and Redis cache as a back-up for low-latency reads. The application layer was managed by Ringpop for request routing, and there was a usage of the Saga pattern for transaction coordination. The Saga pattern, however, added complexity, particularly when handling transactions across multiple objects, such as batch offers to drivers. The new architecture prioritizes strong consistency and linear scalability. After an evaluation in 2018, Uber chose Google Spanner, which moved transaction coordination and scalability concerns to the database layer.
- Shift of focus at the application layer: In the new architecture, the application layer focuses on developing the right programming model for building new fulfillment flows. Transactional data is stored in Spanner, reducing the number of Remote Procedure Calls (RPCs) from Uber’s on-premise data centers to Google Cloud to avoid latency.
- Integrating cache, search, and data streaming systems: For most use cases, Uber’s system can read from an on-premise cache. Spanner is used for strong reads of individual objects and core transactions. A separate search system has been developed for fast, scalable searches across multiple objects. This search system allows for operations like finding unassigned nearby orders. Kafka is used for emitting events in real-time within the Uber stack, aiding in the development of real-time and batch applications.
Our Takeaway:
Uber has shifted its architecture significantly, focusing on consistency and scalability with the introduction of Google Spanner. The application layer has been streamlined, concentrating on building new fulfillment flows, while the management of transaction coordination and scalability concerns has been shifted to the database layer. An integrated cache, search, and data streaming system further optimize the operation, allowing for more efficient data retrieval and real-time event management.
Q5. Uday, would it be accurate to state that the successful alignment between the elements in the application and the database allowed Uber to leverage the transactional strengths of the database at both layers, simplifying coordination at the application level? Additionally, can you explain Uber’s deep hybrid architecture, with part of the application operating on-premise and part leveraging unique services from Google Cloud.
[Note: Uber also uses Oracle Cloud Infrastructure for IaaS services but was out of scope for this discussion. Bob Evans covered this development in a blog post claiming Uber was shuttering it’s own data centers. Our belief is that Uber will maintain some of its own data center infrastructure but will use OCI and Google Cloud across various locations to further minimize latency.
Absolutely. And then I think one more interesting fact is how for most engineers, they don’t even need to understand behind the scenes. They don’t need to know it’s being powered by Spanner or any database. The guarantees that we provide to application developers who are building, for example, fulfillment flows is they have a set of entities and they say, ‘hey, for this user action, these are the entities that need to be transactionally consistent and these are the updates I want to make to them.’ And then behind the scenes are application layer, leverages, Spanners’, transaction, buffering, makes updates to each and every entity, and then once all the updates are made, we commit so then all the updates are reflected in the storage so that the next strong read will be the latest update.
Q6. The database decision obviously was very important. What was it about Spanner that led you to that choice? Spanner is a globally consistent database. What else about it made it easier for all the applications’ data elements to share their status? You said you did a detailed evaluation. How did you land on Spanner?
There are a lot of dimensions that we evaluate, but one is we wanted to build using a NewSQL database because we want to have the mix of, for example, ACID guarantees that SQL systems provide and horizontal scalability that NoSQL kind of systems provide. Building large scale applications using NewSQL databases, at least around that time when we started, we didn’t have that many examples to choose from. Even within Uber we were kind of the first application for managing live orders using a NewSQL based system. But we need external consistency, right?
Spanner provides the strictest concurrency control guarantee for transactions so that when the transactions are committed in a certain order, any specific read after that, they see the latest data. That is very important because, imagine we assigned a particular job to a specific driver or courier, and then next moment if we see that, oh, this driver is not assigned to anyone, we might make a wrong business decision and then assign you one more trip and that that will lead to wrong outcomes.
Then horizontal scalability, because Spanner automatically shards and then it’ll rebalance the shards. And so then we have this horizontal scalability, in fact we have our own autoscaler that listens to our load and Spanner signals and constantly adds new nodes and remove nodes because the traffic pattern Uber has changes based on time of the day and then hour of the day and then also day of the week.
It’s very curvy. So then we can make sure we have the right number of nodes that are provisioned to handle the scale at that point in time. I mentioned the server side transaction buffering, that was very important for us so that we can have a modular application so that each application, each entity that I’m representing, they can commit, update to that entity independently, and a layer above is coordinating across all of these entities. And once all of these entities have updated their part, then we can commit the overall transaction. So the transaction buffering on the server side helped us at the application layer to make it modular.
Then all the things around stale reads, point in time reads, bounded stillness reads, these help us build the right caching layer so that for most reads, our cache rate probably is like on high 60’s, 70 [percent].
So for most reads, we can go to our on-prem cache and only when there’s a cache miss or strong reads, we can go to a storage system. So these were the key things we want from NewSQL.
Then Spanner was the one because, with the time to market, because it’s already productionized and we can leverage that solution, but all of these interactions are behind an ORM layer with the guarantees that we need. So this will help us, over time, figure out if we need to evaluate other options or not. But right now, for most developers, they don’t need to understand what is powering behind the scenes.
Here’s our summary. There are five key aspects around the choice of Spanner and its impact on developers:
- Simplification for developers: Engineers at Uber aren’t burdened with understanding the intricacies of the underlying database system, such as Spanner. Instead, they can focus on developing features and workflows, secure in the knowledge that they can specify entities that must be transactionally consistent and that the system will handle this reliably.
- Why Spanner: Uber wanted to take advantage of the consistency guarantees of SQL systems and the horizontal scalability of NoSQL systems. At the time they were looking, there were not many NewSQL options that fulfilled these requirements. Spanner stood out because it offered external consistency, which ensures that when transactions are committed in a certain order, any subsequent read will see the latest data. This is vital to Uber’s operations as it prevents erroneous decisions based on stale data.
- Scalability: Spanner also provides horizontal scalability, automatically sharding and rebalancing shards, which is important given Uber’s variable traffic patterns.
- Server-side transaction buffering: This feature was essential for Uber, as it allows the system to commit updates to each entity independently. The application layer coordinates across all of these entities, and once each entity has updated its part, the overall transaction can be committed.
- Caching capabilities: Spanner’s features around stale reads, point in time reads, and bounded staleness reads allowed Uber to build an effective caching layer. Most reads can be handled by their on-premise cache, reducing the need to access the storage system directly.
Our Takeaway:
Uber’s system benefits significantly from the use of Google Spanner, which provides consistency, scalability, and efficient transaction handling, among other features. The introduction of Spanner has streamlined operations at the application layer and facilitated the implementation of a reliable caching layer. Importantly, this setup shields most developers from having to understand the complexities of the underlying database technology, letting them focus on the application level concerns.
Q7. Please explain how Uber managed to establish system-wide coherency across its data elements. In other words, how did Uber design and develop technology to ensure a unified understanding or agreement on the definitions of critical elements like drivers, riders, and pricing? We’re specifically interested in the aspects of the system that enable this coherency.
There are many objects we need to think about considering what a user sees in the app that need to be coherent and which ones can be kind of stale, but you don’t necessarily notice because not everything needs to have the same amount of guarantees, same amount of latency and so on, right? So if you think about some of the attributes that we manage, we talked about the concept of orders, if a consumer places any intent that is an order within our system, a single intent might require us to decompose that intent into multiple sub objects. For example, if you place an Uber Eats order, there is one job for the restaurant to prepare the food and there is one job object for the courier to pick up and then drop off.
And for the courier job object, we have many waypoints, which is the pickup waypoint, drop off waypoint, each waypoint can have its own set of tasks that you need to perform. For example, it could be taking a signature, taking a photo, paying at the store, all sorts of tasks, right? And all of these are composable and leverageable. So I can build new things using the same set of objects. And if in any kind of marketplace we have supply and demand and we need to ensure there is a right kind of dispatching and matching paradigms. In some cases, we offer one job to one supply. In some cases it could be image to end, in some cases it is blast to many supplies. In some cases, they might see some other surface where these are all of the nearby jobs that you can potentially handle.
So this is another set of objects which is super real time, because when a driver sees an offer card in the app, it goes away in 30 seconds and in 30, 40 seconds they need to make a decision, and based on that we have to figure out the next step, because, within Uber’s application we have changed the user’s expectation of how quickly we can perform things. If we are off by a few seconds, people will start canceling.
Uber is hyper-local, so we have a lot of attributes around latitude, longitude, route line, driver’s current location, our ETAs. These are probably some of the hardest to get right, because we constantly ingest the current driver location every four seconds, we have lot of latitude longitude. The throughput of this system itself is like hundreds of thousands of updates per second.
But not every update will require us to change the ETA, right? Your ETA is not changing every four seconds. Your routing is not changing every four seconds. So we do some magic behind the scenes to make sure that, okay, have you crossed city boundaries, only then we might require you to update something. Have you crossed some product boundaries, only then we require you to do some things. So we do inferences to limit the number of updates that we are making to the core transactional system, and then we only store the data that we need, and then there’s a complete parallel system that manages the whole pipeline of, for example, how we receive the driver side of equations and generate navigations and stuff for drivers, and then how we convert these updates and then show it on the rider app. That stream is completely decoupled from the core orders and jobs.
And if you think about Uber system, it’s not just about building the business platform layer. We have a lot of our own sync infrastructure at the edge API layer because we need to make sure all of the application data is kept in sync. They’re going through choppy network conditions, they might be unreliable, and we need to make sure that they get the updates as quickly as possible with low latency, irrespective of what kind of network condition they are in. So there’s a lot of engineering challenges at that layer as well.
Ultimately, all of this is working together to provide you the visibility that I can exactly see what’s going on, because if you’re waiting for your driver, if they don’t move, you might cancel assuming that they might not show up. And we need to make sure that those updates flow through, not just our system, but also from our system back to the rider app as quickly as possible.
[Watch Uday describe how Uber managed to establish system-wide coherency across its data elements].
Our Takeaway:
Uber’s system is a complex web of various components working in tandem to ensure smooth operations and a positive user experience. Data is categorized based on its necessity for real-time updates, and Uber has built technology to intelligently determine when updates are needed. This helps to maintain a harmonious data environment that can handle numerous scenarios, ensuring coherency across all its data elements.
Our analysis suggests that Uber’s current system operates on two distinct layers: the application layer and the database layer. At the application layer, Uber manages various entities or “things,” and it effectively translates these entities down to the database layer. The transactional semantics of the database make it easier to manage and coordinate these entities.
However, this also highlights that Uber treats the ‘liveliness’ of data as a separate attribute, which allows the company to manage data updates and communication in a way that isn’t strictly tied to its representation in the database. This strategy involves managing updates based on specific properties of each data element.
This approach is noteworthy, especially in light of previous discussions with Walmart, which highlighted the importance of data prioritization and efficient communication from stores and other edge locations.
Our assertion is that Uber’s strategy could provide a model for other businesses that need to manage complex, real-time data across distributed systems.
How Orchestrating Real World Entities is Different
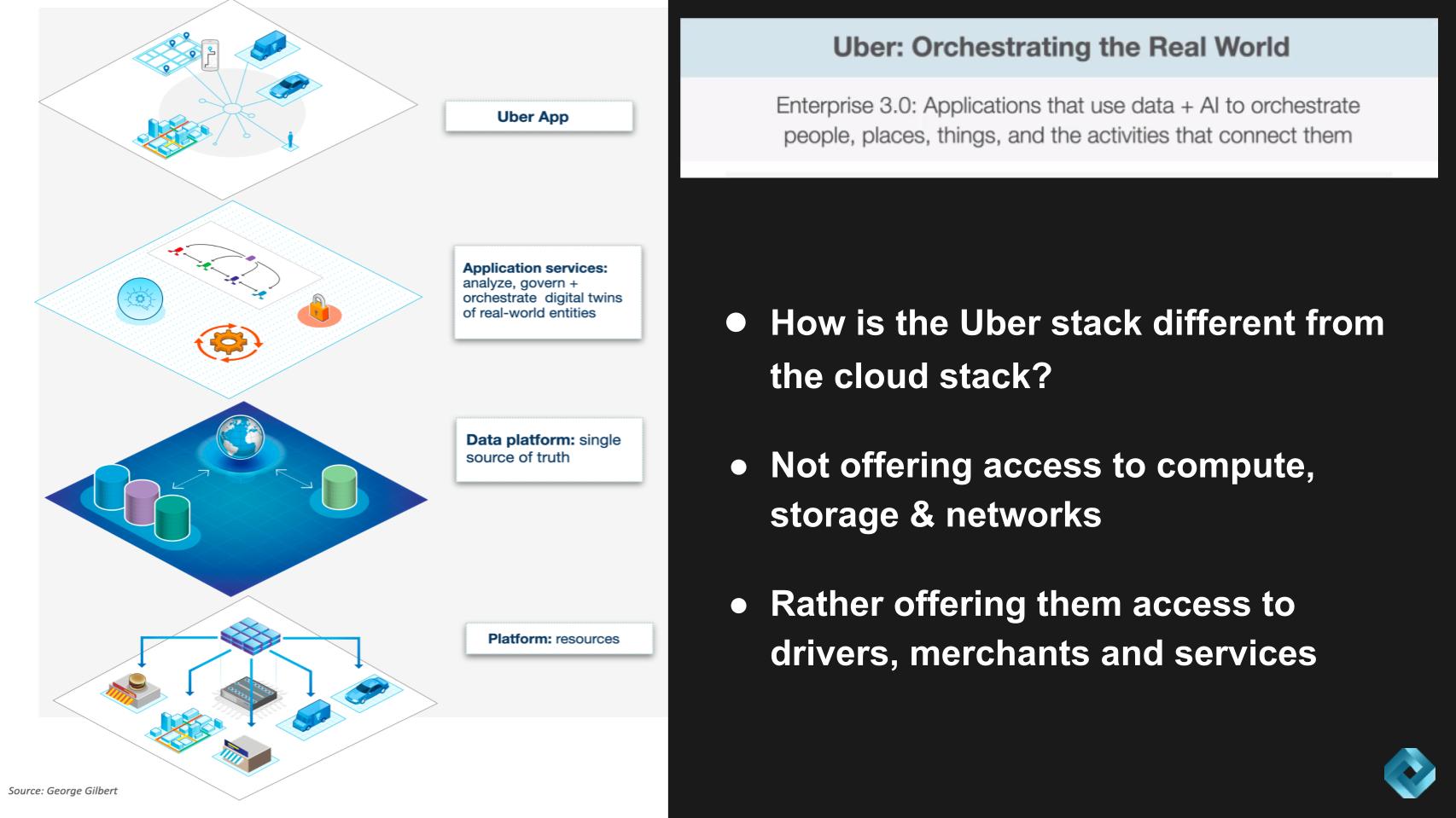
The chart above attempts to describe these 3.0 apps where starting at the bottom you have the platform resources then the data layer to provide the single version of truth and then the application services that govern and orchestrate the the digital representations of the real world entities – drivers, riders, packages, etc. and that all supports what the customers see – i.e. the Uber app.
A big difference from the cloud stack that we all know is you’re not directly aware of consuming compute and storage, rather Uber is offering up physical “things” – access to drivers, merchants, services etc. – and translating that into software.
Where are the lines between the commercial off the shelf software you were able to use and the IP Uber had to develop itself to achieve its objectives – can you describe that process and what you had to build vs. buy?
Q8. Uday, could you explain how Uber decided between using commercial off-the-shelf software and developing its own intellectual property to meet its objectives? Could you outline the thought process behind the ‘build versus buy’ decisions you made and the role of open source software?
In general, we rely on a lot of open source technologies, commercial off-the-shelf software, and in some cases, in in-house developed solutions. Ultimately it depends on the kind of specific use case, time to market, maybe you want to optimize for cost, optimize for maintainability. All of these factors come into picture. For the app, the core orders and the code fulfillment system, we talked about Spanner and how we leverage that with some specific guarantees. We use Spanner for even our identity use cases where we want to manage, for example, especially in large organizations, we want to make sure your business rules, your AD groups, your stuff, how we capture that for our consumers that has to be in sync.
But there is a lot of other services across microservices, across Uber that leverage Cassandra, if their use case is high ride throughput. And we leverage Redis for all kinds of caching needs. We leverage Zookeeper for low level infrastructure platform storage needs. And we also have a system that is built on top of MySQL with an RAF-based algorithm called DocStore. So for the majority of the use cases, that is our go-to solution where it provides you shard local transactions and it’s a multi model database. So it’s useful for most kind of use cases and it’s optimized for cost, because we manage the stateful layer, we manage and we deploy it on our nodes. So for most applications, that will give us the balance of cost and efficiency and for applications that need the strongest level of requirements like fulfillment or identity where we use Spanner, for higher ride input, we use Cassandra.
And beyond this when we think about our metrics system, M3DB, it’s an open source software, open source by Uber, contributed to the community few years ago, it’s a time series database. We ingest millions of metric data points per second and we had to build something on our own. And now it’s an active community and there’s a bunch of other companies leveraging M3DB for metric storage.
So ultimately, in some cases we might have built something and open sourced it in some cases we leverage off the shelf, in some cases we use completely open source and contribute some new features. For example for, for DataLake, Uber pioneered Apache back in 2016 and contributed. So then we have one of the largest transactional data lakes with maybe 200 plus petabytes of data that we manage.
Our Takeaway:
Uber’s approach demonstrates a balance between using off-the-shelf and open-source solutions, contributing to open source projects, and developing in-house solutions. This strategy is determined by factors such as specific use cases, time-to-market considerations, cost-efficiency, and maintainability. It underscores the importance of a diversified strategy in software and database solutions to meet the unique needs of various operations.
The Value of Real-Time Data Apps
This next snippet we’re sharing comes from an ETR roundtable.

Everybody in the world is thinking about real-time data. And whether it’s Kafka specifically or something that looks like Kafka, real time, stream-processing is fundamental. When people talk about a data-driven business they very quickly come to the realization that they need real time because that’s where there’s more value. Architectures built for batch do not do real time well. Cockroach is super exciting. I feel weird endorsing a small startup, but Google Spanner is amazing, and Cockroach is the closest thing that you could actually buy [off the shelf] and run yourself, rather than be married to managed service from a single cloud vendor.
Q9. Uday, how did Uber change the engine in mid-flight going from the previous architecture without disrupting its business?
Designing a [pure] greenfield system is one thing, but moving from whatever you have to [a new] system is 10X harder. The hardest engineering challenges that we had to solve for was how we go from A to B without impacting any user. We don’t have the luxury to do a downtime where, ‘hey, you know, we’re going to shut off Uber for an hour and then let’s do this migration behind the scenes.’ We went through how, the previous system was using Cassandra with some in-memory queue, and then the new system is strongly consistent. How do you go from, the core database guarantees are different, the application APIs are different, so what we had to build was a proxy layer that for any user request, we have a backward compatibility, so then we shadow what is going to the old system and new system.
But then because the properties of what transaction gets committed in old and new are also different, it’s extremely hard to even shadow and get the right metrics for us to get the confidence. Ultimately, that is the shadowing part. And then what we did was we tagged a particular driver and a particular order that gets created, whether it’s created in the old system or new system, and then we gradually migrate all of the drivers and orders from old to new. So there would be at a point in time you might be seeing that marketplace is kind of split where half of those orders and earners are in the old, half of them are in the new, and then once all of the orders are moved, we switch over the state of remaining earners from old to new.
So one, we had to do a lot of unique challenges on shadowing, and two, we had to do a lot of unique tricks to make sure that we give the perception of there is no downtime and then move that state without losing any context, without losing any jobs in flight and so on. And then if there is a driver who’s currently completing a trip in the old stack, we let that complete and the moment they’re done with that trip, we switch them to the new stack so that their state is not transferred midway through a trip. And so once you create new trips and new earners through new and then switch them after they complete the trip, we have a safe point to migrate. This is similar to 10 years ago, I was at VMware and we used to work on how do you do vMotion…virtual machine migration, from one host to another host, so this was kind of like that challenge.
What is the point at which you can split, you can move the state without having any application impact? So those are the tricks that we had to do.
Q10. How is Uber planning to manage a future where the ecosystem could be 10 or 100 times larger with more data than currently? And have you considered scenarios where the centralized database might not be the core of your data management strategy? In other words, when does this architecture run out of gas?
That’s where the trade offs come in. We need to be really careful about not putting so much data in the core system that manages these entities and these relationships and overwhelm it with so much data that we’ll end up hitting scale bottlenecks. For example, the fare item that you see both on the rider app or on the driver app, that item is made up of hundreds of line items with different business rules, specific different geos, different localities, different tax items. We don’t store all of that in the core object. But one attribute for a fare that we can leverage is a fare only changes if the core properties of rider’s requirements change.
So every time you change your drop off, then we regenerate the fare. So I have one fare UID. Every time we regenerate, we create a new version of that fare and store these two UIDs along with the core order object so that I can store in a completely different system my fare UID, fare version, and all of the data with all of the line items, all of the context that we use to generate those line items. Because what we need to save transactionally is the fare version UID. When we save the order, we don’t need to save all of the fair attributes along with that. So these are some design choices that we do to make sure that we limit the amount of data we store for these entities. In some cases we might store the data, in some cases we might version the data.
In some cases, if it is okay to tolerate that data and it doesn’t need to be coherent with the core orders and jobs, it can be saved in a completely different online storage. And then we have at the presentation layer where we generate the UI screen. There, we can enrich this data and then generate the screen that we need. So all of this will make sure that we limit the scale of growth of the core transactional system and then we leverage other systems that are more suited for the specific needs of those data attributes. But still all of them tie into the order object and then there’s an association that we maintain.
So, how do we make sure we don’t run out of gas? Obviously we are doing our own scale testing, our own projected testing to make sure that we are constantly ahead of our growth and make sure the system can scale, and then we are also very diligent about looking at the properties of the data, choosing the right technology so that we limit the amount of data that we store for that system and then use specific kind of systems that are catered to those use cases.
For example, all of our matching system, if it wants to query all of the nearby jobs and nearby supplies, we don’t go to the transactional system to query that. We have our own inbuilt search platform where we are doing real time ingestion of all of this data using CDC and we have all kinds of anchors so that we can do real time, on the fly generation of all of the jobs because the more context you have, the better marketplace optimization we can make and that can give you the kind of efficiency at scale, right? Otherwise, we’ll make imperfect decisions, which will hurt the overall marketplace efficiency.
Q11. Uday, how do you envision the future of commercial tools in the next three to five years that could potentially simplify the process for mainstream companies, without the extensive technical resources like Uber, to build similar applications? Specifically, do you foresee a future where these companies can manage hundreds of thousands of digital twins using more off-the-shelf technology? Is this a plausible scenario in the midterm future?
I think the whole landscape around developer tools, applications, it’s a rapid evolving space. What was possible now was not possible five years ago. And it’s constantly changing. But what we see is we need to provide value at upper layers of the stack, right? And then if there is some solution that can provide something off the shelf, we move to that so then we can focus up the layer. Like it’s not just building, taking off the shelf or past solutions. Just taking the sheer complexity of representing configuration, representing the geo-diversity around the world, and then building something that can work for any use case in any country adhering to those specific local rules, that is what I see as the core strength of Uber.
We can manage any kind of payment disbursements or payments in the world. We have the largest support for many payment, like any payment method in the world for earners who are disbursing billions of payouts to whatever bank account and whatever payment method they need money in. We have a risk system that can handle nuanced use cases around risk and fraud. Our system around fulfillment that’s managing this, our system around maps that is managing all of the ground tolls, surcharges, navigation, all of that, so we have probably one of the largest global map stacks where we manage our own navigation and leveraging some data from external providers. So this is the core IP and core business strength of Uber and that is what is allowing us to do many verticals, but again, the systems that I can use to build this that over time, absolutely I see it makes it easier for many companies to leverage this. Maybe 15 years ago we didn’t have Spanner, so it was much harder to build this. Now with Spanner or with similar new off-the-shelf databases, it solves one part of the challenge, but then other challenges will emerge.
Final Thoughts
Uber has had an immense impact, not just in software development, but also in transforming the way business is conducted. Similar to how Amazon.com pioneered managing its internal processes. By orchestrating people, places, and things on an internal platform, Uber has done something similar but on a more significant scale. They have done this for an external ecosystem, making it accessible to consumers in real time.
However, a major question remains – how will the industry develop technology that allows mainstream companies to start building their own platforms to manage their ecosystems, akin to Uber’s model? We believe Uber points the way to the future of real-time, data-driven applications but the exact path the industry takes is an an intriguing question for the future.
Keep in Touch
Many thanks to Uday Kiran Medisetty for his collaboration on this research. Thanks to Alex Myerson and Ken Shifman on production, podcasts and media workflows for Breaking Analysis. Special thanks to Kristen Martin and Cheryl Knight who help us keep our community informed and get the word out. And to Rob Hof, our EiC at SiliconANGLE.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com | DM @dvellante on Twitter | Comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail.
Watch the full video analysis:
Image:ifeelstock
Note: ETR is a separate company from Wikibon and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai.
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of Wikibon. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.

